Introdução à Visualização de Dados¶
A visualização de dados é interdisciplinar e agregadora a qualquer pessoa interessada em manusear ou apresentar dados de forma qualitativa ou quantitativa. Ela não se restringe a áreas de formação específica, mas algumas características essenciais para o desenvolvimento de habilidades na disciplina são:
familiaridade com estatística;
vontade de aprender coisas novas;
curiosidade para descobrir respostas;
apetite por princípios de design;
disposição para aumentar seu rigor analítico e
conhecimento técnico de pelo menos uma ferramenta para plotagem.
Pontos de equilíbrio¶
A visualização de dados gera diversas dicotomias em sua trilha de aprendizagem. Podemos enviesar seu estudo para uma direção ou outra, dependendo dos interesses. Algumas perguntas que suscitam a busca por pontos de equilíbrio são as seguintes:
É melhor aprender visualização de dados através de um guia ou manual, que discute princípios, conceitos e orientações, ou através de um tutorial, que contém exemplos de código e demonstrações de gráficos incríveis?
Devemos dissertar sobre as nuances artísticas, com toda a beleza do design, ou sobre a elegância simples e útil do cotidiano?
Faz sentido compreender conceitos teóricos da visualização de dados, ou ser apenas pragmático?
Vale seguir o exemplo dos livros pioneiros e clássicos ou prezar pelo contemporâneo?
O que queremos com os dados: prover um arcabouço analítico de exploração e interatividade (visualização para análise), ou apenas comunicá-los a uma audiência para gerar impacto e atratividade (visualização para comunicação)?
As respostas para essas questões não são binárias. Futuros profissionais que farão uso de tudo o que a visualização de dados tem a oferecer devem ser suficientemente flexíveis para encontrar seus pontos de equilíbrio particulares para cada situação apresentada.
Visão geral do curso¶
Levando em consideração a necessidade por pontos de equilíbrio, este curso pretende abordar a visualização de dados em três módulos:
Fundamentos: dedicado ao estudo dos conceitos primários da visualização de dados, tais como desenvolvimento histórico, princípios, percepção, estética e cores.
Técnicas: focado na discussão de técnicas diversas para representação visual de quantidades, proporções, tendências, redes e outros tipos de dados através de exemplos de códigos.
Aplicações: dedicado à apresentação de ferramentas e plataformas modernas para construção de painéis analíticos (dashboards), soluções de data reporting e inteligência de negócios (business intelligence) por meio de tutoriais simplificados ou workshops.
Arquitetura visual x engenharia visual¶
A audiência deste curso não deve esperar que ele seja puramente técnico, tampouco integralmente teórico. Entretanto, os objetivos de formação miram estudantes com razoável conhecimento de técnicas estatísticas e de programação. Portanto, não haverá aprofundamento em temas inerentes à arte e ao design. Se chamássemos de arquitetura visual a área profissional que cuida da especificação dos projetos de visualização de dados, e de engenharia visual a área que executa tais projetos, diríamos que este curso abrange majoritariamente a segunda.
Definindo Visualização de Dados¶
A disciplina visualização de dados é considerada recente sob o prisma teórico. Existem muito mais recomendações de princípios a serem seguidos do que, efetivamente, uma organização estruturada de conhecimento para lhe dar sustentação científica. A maioria dos praticantes na área entende que visualizar dados é um misto entre arte e técnica, até porque a humanidade é composta de seres substancialmente visuais. Não por acaso o clichê “uma imagem vale mais que mil palavras” tornou-se popular.
Curiosidade
A origem da expressão “uma imagem vale mais que mil palavras” ("a picture is worth a thousand words") deriva de um provérbio chinês supostamente propagado pelo filósofo Confúcio (551 - 479 AEC). Na América do século XX, a forma moderna desse adágio é atribuída a Fred Barnard, anunciante que viveu na década de 1920.
Saber encontrar a dosagem entre arte e técnica (ou ciência) é fundamental para que dados sejam comunicados com máxima precisão e eficiência, assim evitando equívocos e distorções. De certa forma, a representação visual da informação deve ser suficientemente agradável aos olhos de seu espectador sem, no entanto, interferir na mensagem que ela retrata. Um pouco mais adiante, discutiremos melhor esse contraste.
Neste curso, usaremos a seguinte definição, adaptada de Andy Kirk:
Visualização de dados é a arte de combinar representações visuais e apresentações para facilitar a compreensão dos dados.
A representação visual (chart), ou simplesmente RV, é o elemento que melhor se adéqua ao que se pretende comunicar. Charts têm marcadores e atributos como seus fundamentos, como veremos em capítulos posteriores. A apresentação visual concerne a todas as outras tomadas de decisão de design que constituem a anatomia da visualização, tais como a seleção da paleta de cores, a composição da obra e as características das anotações. Ambas constituem a parcela artística do autor e o âmago da disciplina. A execução disso tudo independe da ferramenta técnica utilizada. Existem diversos sistemas, pacotes, bibliotecas e linguagens disponíveis, sendo R e Python as linguagens de programação preferidas dos analistas de dados.
Por outro lado, a parte final da definição, que diz respeito à compreensão facilitada dos dados, tem a ver com o processo de captura da mensagem lançada pelo contador de história (storyteller) ao espectador (viewer). Este processo envolve 3 etapas cognitivas (Figure 1, adaptada de 1):
Percepção (o que vejo?)
Interpretação (o que significa?)
Compreensão (o que significa para mim?)
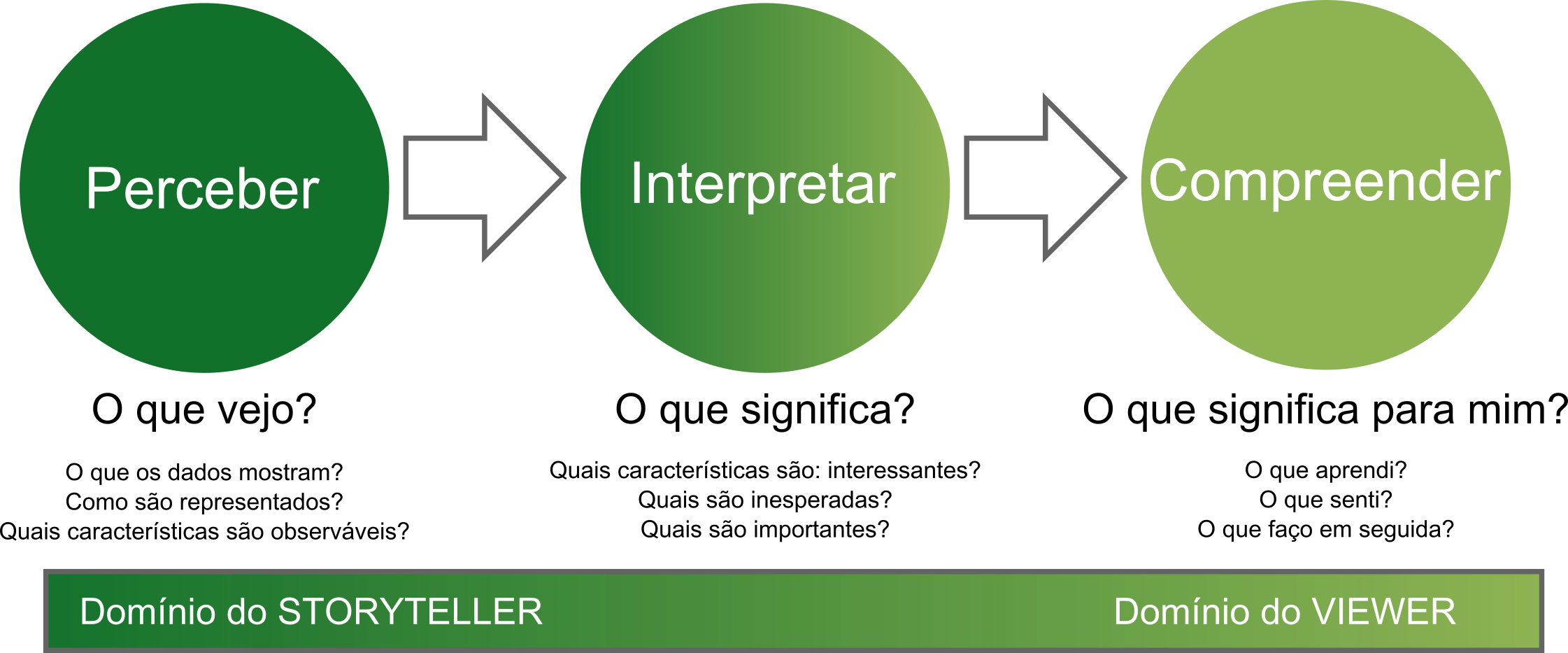
Figure 1:As 3 fases da compreensão de uma representação visual. Preparada por: G.P. Oliveira.
Figuras feias, ruins e erradas¶
Diferentes versões de figuras com a mesma RV subjacente podem existir (Figure 2, adaptada de 2). Porém, uma delas pode ser feia, outra pode ser ruim e outra pode ser errada. Esse mecanismo tripartite é um exemplo de como podemos fazer julgamentos de trabalhos visuais. Segundo Claus Wilke, uma figura:
feia é aquela que tem problemas estéticos, apesar de clara e informativa.
ruim é aquela que tem problemas relacionados à percepção, tais como obscuridade, confusão, complicações e enganação.
errada é aquela que tem problemas relacionados à matemática e é objetivamente incorreta.
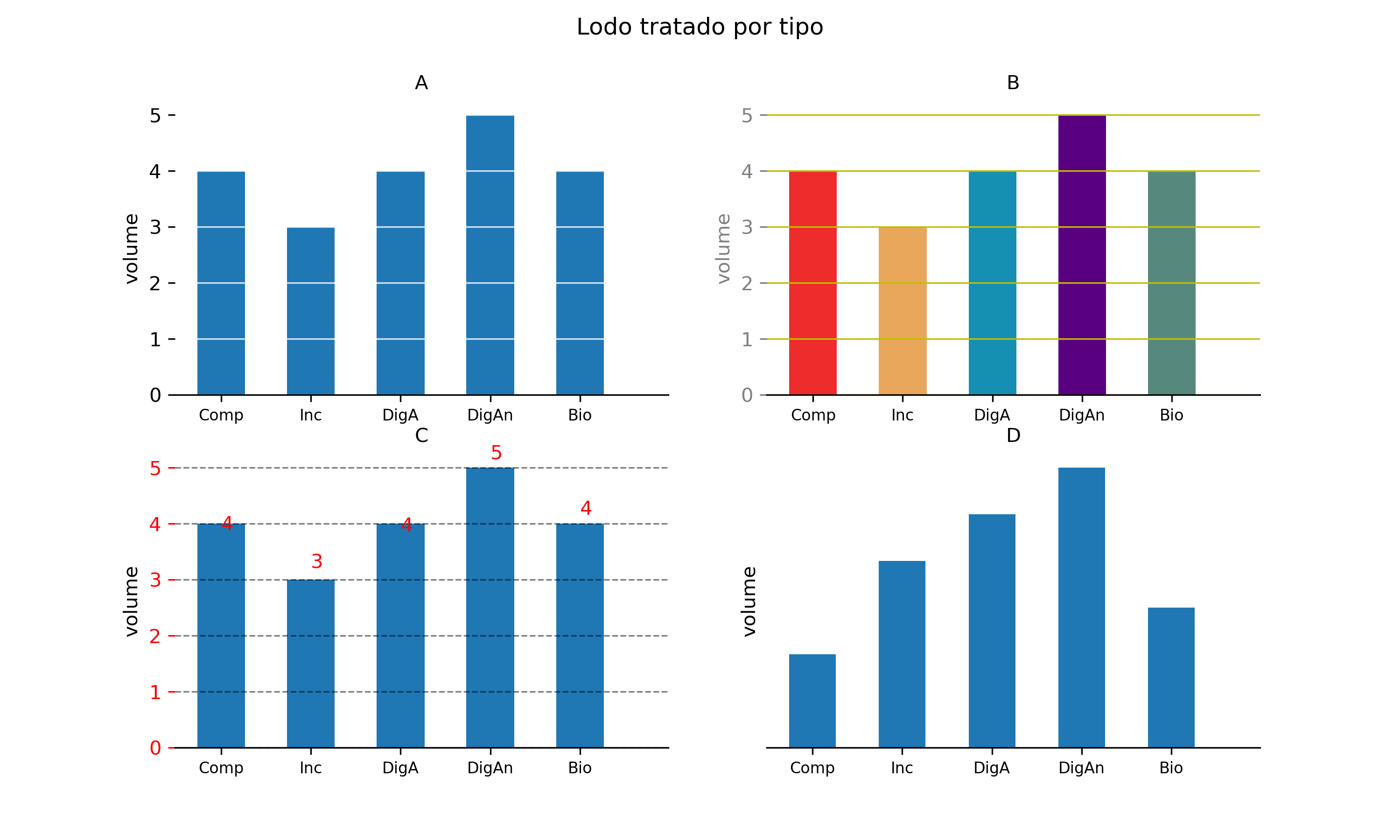
Figure 2:Comparação de figuras: A) adequada, sem problemas aparentes graves; B) versão “feia”, tecnicamente correta, mas colorida inutilmente; C) versão “ruim”, também tecnicamente correta, mas com marcações e gradeado destoantes; D) versão “errada”, sem escala explícita e aparentemente díspar em quantidade. Preparada por: G.P. Oliveira.
Curiosidade
The Good, the Bad and the Ugly, em português “Três homens em conflito”, filme clássico de western lançado em 1966 que consagrou a trilha sonora do “assobio” de Ennio Morricone, conta a história de três homens, Tuco, Lourinho e Angel Eyes, que procuram por um tesouro. Dois deles (Tuco e Lourinho) apenas têm conhecimento de uma parte da sua localização, ao passo que Angel Eyes somente persegue os outros dois por não ter informação nenhuma. No final, o Bom é o “mais ético”, o Feio é o “mais rude e de aparência tosca” e o “mau” é o “mais displicente”.
Dataviz, o pensamento visual e o bom plot¶
A era da informação hoje entende que a visualização de dados, comumente conhecida pelo pseudônimo dataviz (de data visualization), é uma disciplina obrigatória para um novo modo de pensar: o pensamento visual. No mundo dos negócios, pensar visualmente é ser capaz de construir representações visuais com grande potencial atrativo. Para empresas competitivas, a mensagem clara e acessível transmitida graficamente é uma das grandes vantagens de marketing.
Como já dissemos, adjetivar um plot com características visuais apreciáveis como “bom” é uma questão de seguir princípios que ajudam a definir por que construi-lo de um jeito e não de outro. A Matriz da Boa Representação Visual (Figure 3, adaptada de 3), sugere que um plot considerado “bom” deve aproximar-se cada vez mais da quina superior direita, onde reside a perfeição.
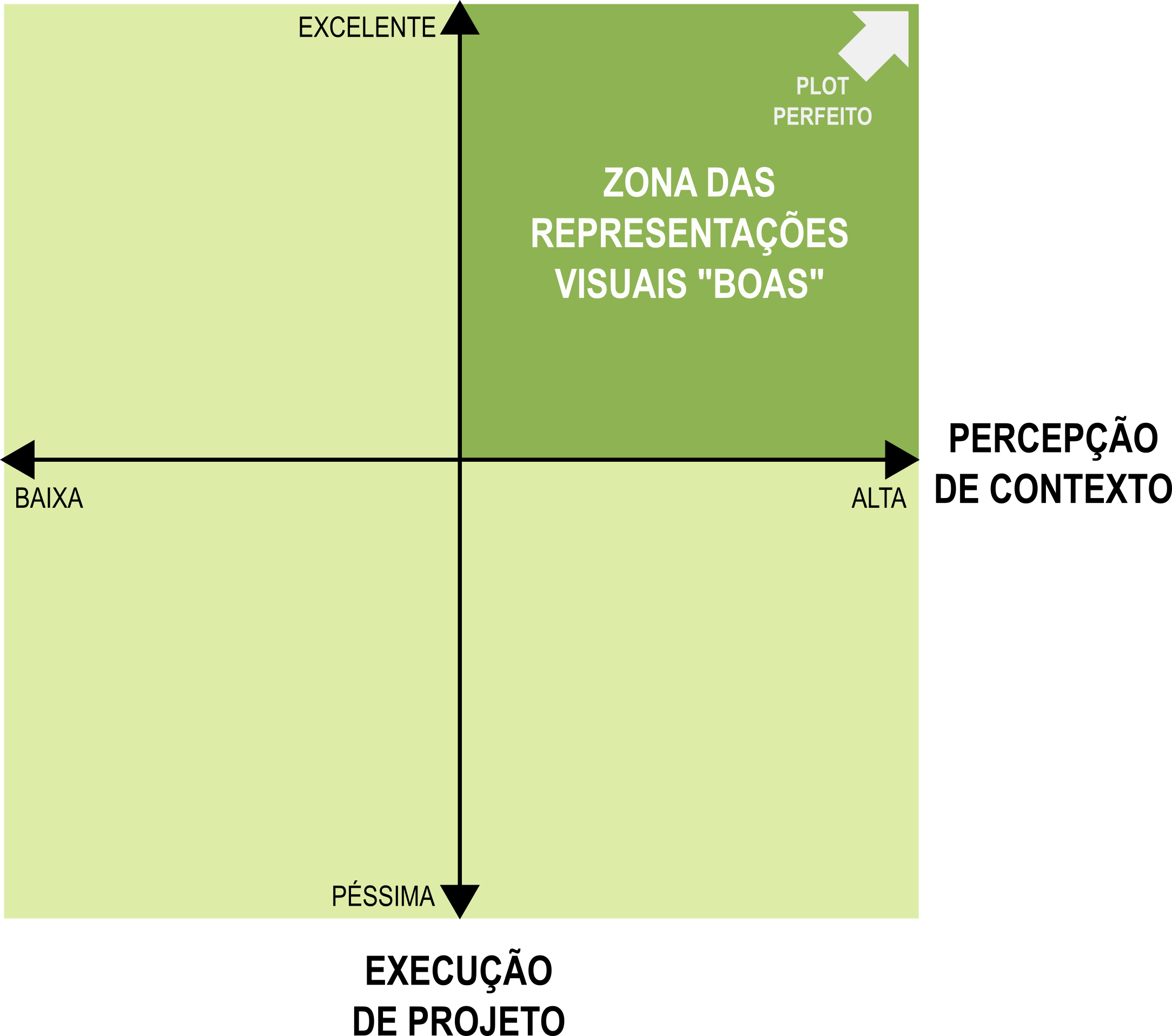
Figure 3:Matrix da Boa Representação Visual. Preparada por: G.P. Oliveira.
Os princípios de Tufte¶
Edward Tufte, um estatístico americano reconhecido como o maior expert em visualização de dados estatísticos da atualidade, escreveu diversos livros sobre excelência visual, visualização da informação quantitativa e arte em imagens. Tufte destaca uma série de critérios que, se obedecidos, garantirão excelentes plots e gráficos. Ele defende que uma RV eficaz mistura substância, estatística e arte (design), caracterizando-se como uma apresentação bem elaborada de dados interessantes. Para Tufte, o espectador deve compreender o maior número de ideias em um intervalo de tempo curto olhando para algo que usa pouca tinta e ocupa o menor espaço possível.
Na visão de Tufte (4,5), a RV excelente deve:
apresentar dados;
induzir o espectador a pensar a substância da RV e não os métodos ou técnicas que a estruturaram;
evitar distorcer os dados;
apresentar muitos números em um espaço mínimo;
tornar grandes dados coerentes;
encorajar os olhos a compararem diferentes partes dos dados;
revelar os dados em vários níveis de detalhe, do mais amplo ao mais específico;
servir a um propósito claro: descrever, explorar, tabelar e decorar; e
estar estreitamente vinculada às descrições estatísticas e verbais dos dados.
Alguns princípios fundamentais de Tufte incorporam todas as expectativas acima:
Integridade visual: a figura não deve, de forma alguma, distorcer ou criar falsas interpretações dos dados. Isto significa que quantidades numéricas devem ser proporcionais aos elementos contidos na superfície da figura. Variações nos dados são permitidas, mas variações da figura não. Adicionalmente, deve-se manter o número de dimensões da imagem em quantidade igual ou inferior as contidas nos dados. Legendas devem ser usadas sem distorção ou ambiguidade. Tufte enfatiza que representações visuais de excelência projetadas por artistas sem nenhuma competência estatística são raras, já que a tendência de se produzir artefatos artísticos ambíguos é consideravelmente alta.
Maximização da razão “tinta-dados”: para Tufte, o storyteller precisa atentar para a quantidade de elementos agregados em uma RV. Sobrecarregar a interpretação do leitor com elementos geométricos, bordas, cores de fundo, efeitos 3D, entre outros adereços, é um ponto negativo para a compreensão final. A maneira sugerida de controlar a superfluidade visual é calcular a quantidade de tinta necessária para representar os dados reais sem ambiguidade e comparar com a quantidade de tinta utilizada para enriquecer a figura com decorações. A equação para o que Tufte chamou de razão “tinta-dados” (data-ink ratio), aqui denotada por é:
onde , , e denotam, nesta ordem, a quantidade de tinta usada para os dados, para os adereços e para ambos, no total. Maximizar a implica em eliminar do visual aquilo que é inútil ou não essencial.
Estética: a elegância visual só pode ser atingida ao se equilibrar a complexidade dos dados com a simplicidade do design. Para criarmos representações visuais com alto nível de profisssionalismo, é preciso muita dedicação, atenção e esmero de projeto. Ou seja, a estética perfeita só é atingida com pleno domínio do ferramental técnico e criatividade.
Integridade ou falta dela?¶
A Figure 4 é uma representação visual que mistura gráficos de barras com a fotografia do ilustre Cristiano Ronaldo. Nada contra o lendário “CR7”, mas, será que, em termos de integridade visual, seria necessária a estampa gigantesca de sua imagem ali? Ela é útil para os dados. Torna-se evidente que há muito mais peso de marketing do que de dados.
Em segundo lugar, você consegue notar que a escala de valores é grosseiramente desproporcional? A barra indicadora de 10.000 unidades vendidas para o nosso “brazuca” Neymar está bastante esticada em relação às outras duas, não é?
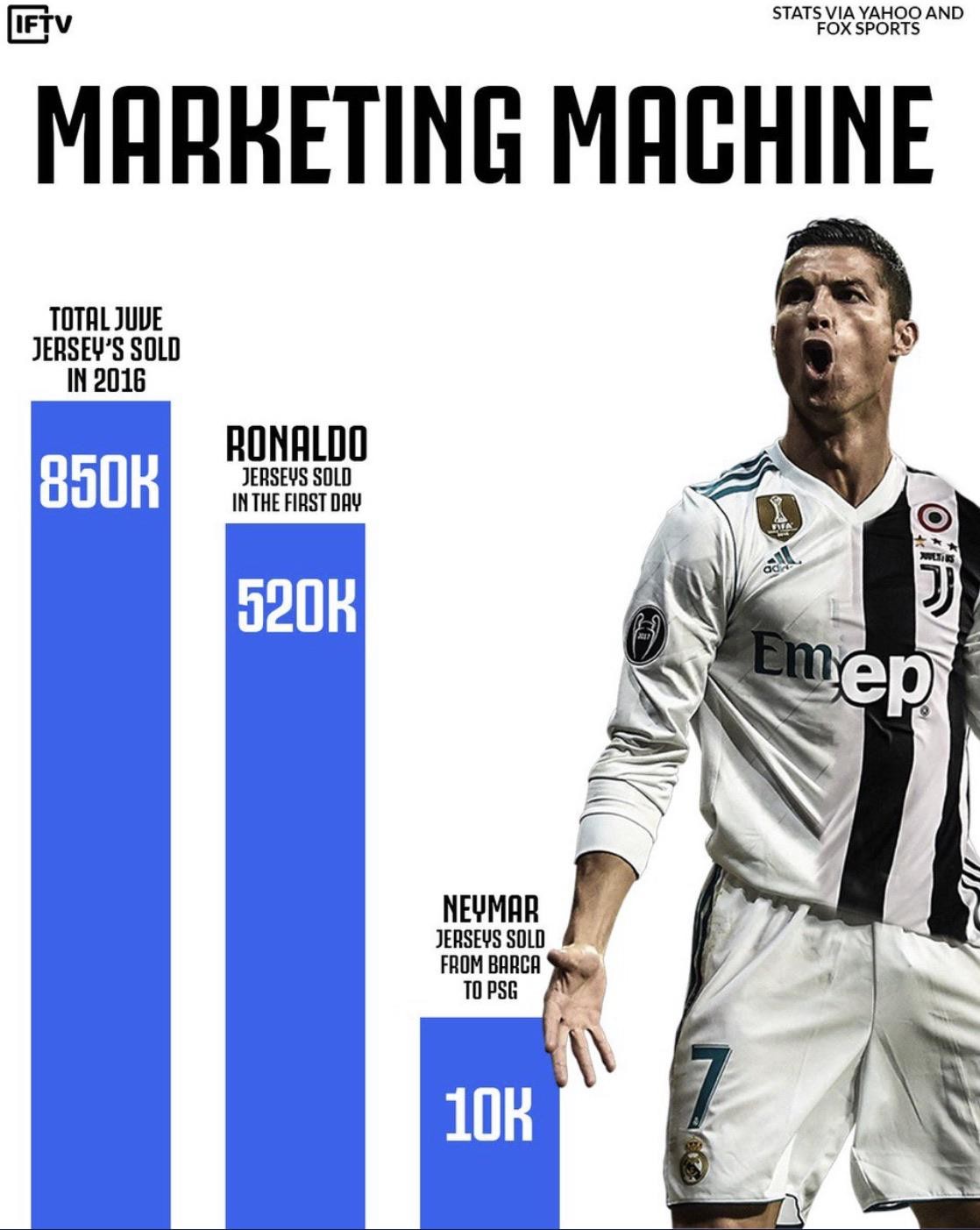
Figure 4:Número de camisas jersey de alguns jogadores vendidas. Fonte: clique aqui.
Diante desse problema de desproporcionalidade e marketing apelativo, há duas coisas a fazer para darmos integridade visual à nossa representação visual: elminar a imagem do jogador e corrigir a escala. Um gráfico clean, porém íntegro, seria como o da A Figure 5
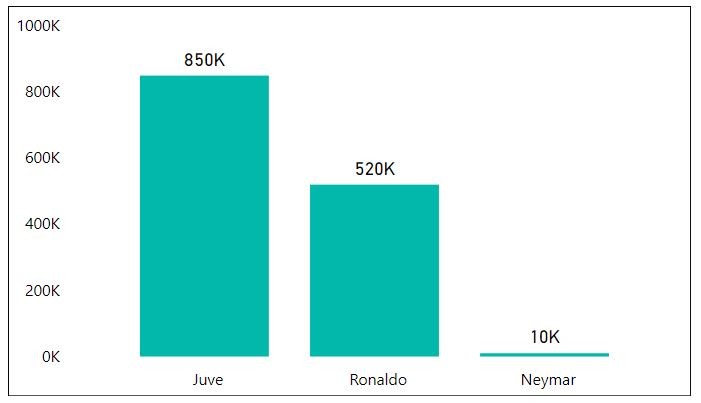
Figure 5:Número de camisas jersey de alguns jogadores vendidas. Versão corrigida para integridade visual.
Maximizando a razão tinta-dados na prática¶
Maximizar a RTD é um processo puramente experimental e iterativo. Só chegamos a bom termo em uma RV após alterações, remoções, adições, reestruturações. O gráfico de barras da Figure 6 mostra a distribuição calórica de algumas comidas “sujas”. Em sua versão original, a RV é abarrotada de cores e redundâncias.
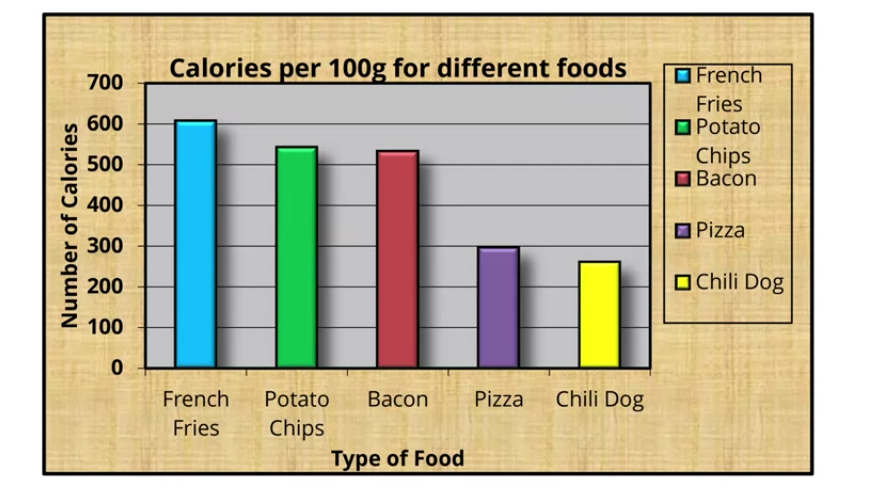
Figure 6:Exemplo de maximização da razão tinta-dados em dados sobre comidas “sujas” - RV 1. Fonte: clique aqui.
Consideremos agora um processo iterativo que gerará uma RV minimalista a partir do melhoramento sucessivo das anteriores. Os passos são os seguintes:
Figure 7: removemos as cores de background (figura e eixos), pois nada acrescentam.
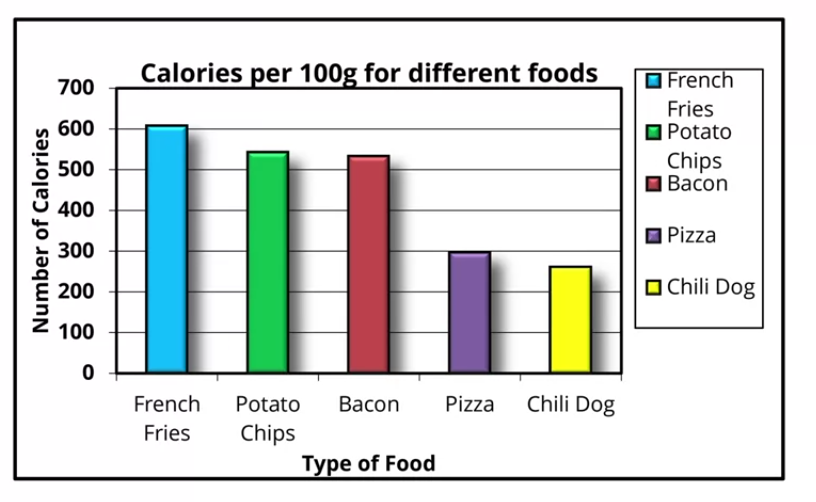
Figure 7:Exemplo de maximização da razão tinta-dados em dados sobre comidas “sujas” - RV 2. Fonte: clique aqui.
Figure 8: removemos redundâncias (título, legenda e designações de eixo).
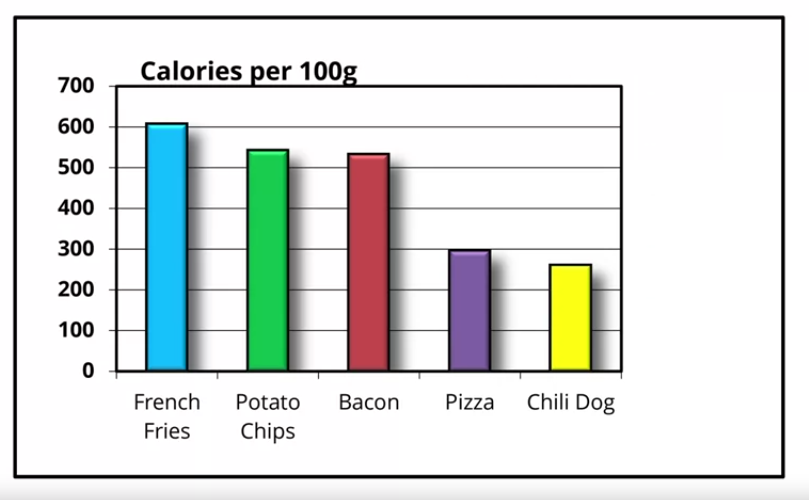
Figure 8:Exemplo de maximização da razão tinta-dados em dados sobre comidas “sujas” - RV 3. Fonte: clique aqui.
Figure 9: removemos bordas, visto que adicionam apenas tinta.
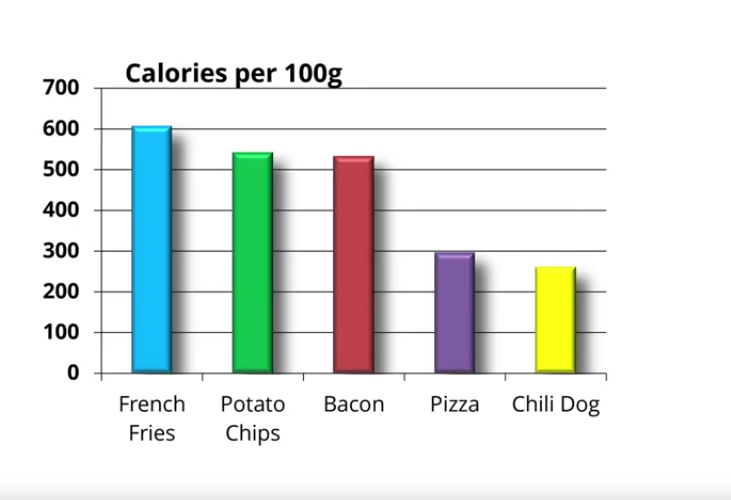
Figure 9:Exemplo de maximização da razão tinta-dados em dados sobre comidas “sujas” - RV 4. Fonte: clique aqui.
Figure 10: reduzimos as cores e damos destaque a uma comida específica. No caso, bacon.
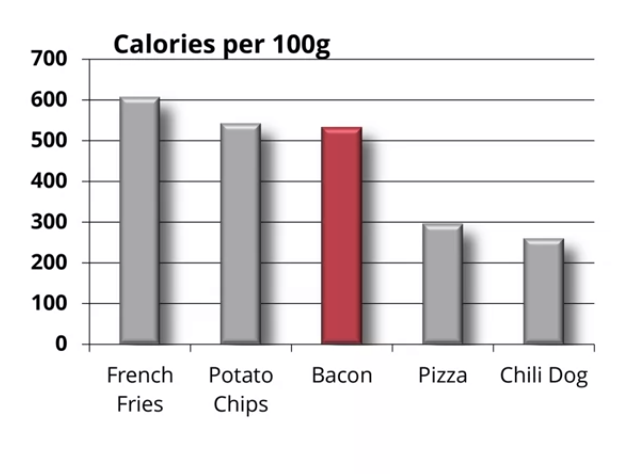
Figure 10:Exemplo de maximização da razão tinta-dados em dados sobre comidas “sujas” - RV 5. Fonte: clique aqui.
Figure 11: neste ponto, a RTD aumentou consideravelmente. Porém, podemos otimizá-la retirando efeitos 3D e sombras.
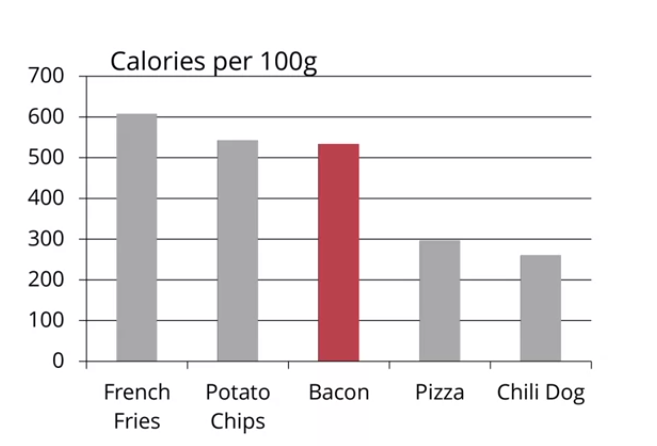
Figure 11:Exemplo de maximização da razão tinta-dados em dados sobre comidas “sujas” - RV 6. Fonte: clique aqui.
Figure 12: por fim, retiramos o gradeado, já que podemos indicar valores embutidos. Enfim, chegamos a uma RV minimalista.
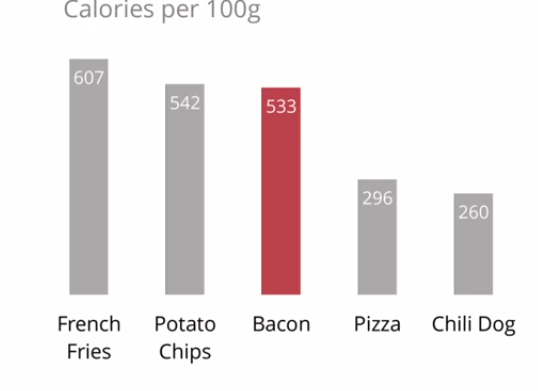
Figure 12:Exemplo de maximização da razão tinta-dados em dados sobre comidas “sujas” - RV final. Fonte: clique aqui.
Estética: quem ajuda não deve atrapalhar¶
A elegância visual só pode ser atingida ao se equilibrar a complexidade dos dados com a simplicidade do design. Nas RVs representadas na Figure 13 e Figure 14, o gradeado é um elemento adicional que agrava a estética dos dados representados. Porém, se ele for retirado, juntamente com outros dados, nada pode ser dito sobre as curvas. Removê-lo ajuda em algo, mas também implica em obscurecimento do que se pretende comunicar.
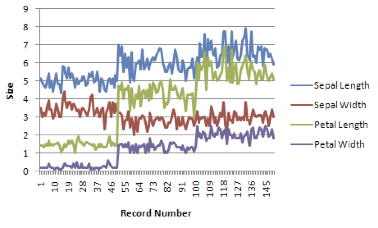
Figure 13:Exemplo de estética depauperada - com gradeado. Fonte: clique aqui.
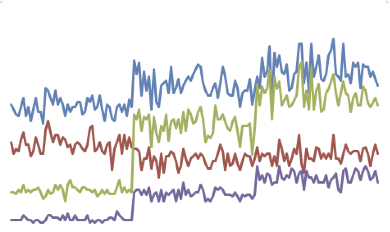
Figure 14:Exemplo de estética depauperada - sem gradeado. Fonte: clique aqui.
O caso da Figure 15 já é de desequilíbrio nas escalas dos eixos de lateralidade e de profundidade em virtude da visualização tridimensional. O gráfico lembra uma cidade infestada de prédios. A questão é: dá para ver o que tem atrás dos “arranha-céus” alaranjados? Este é um exemplo de visualização multidimensional que poderia ser melhor representada menor dimensão.
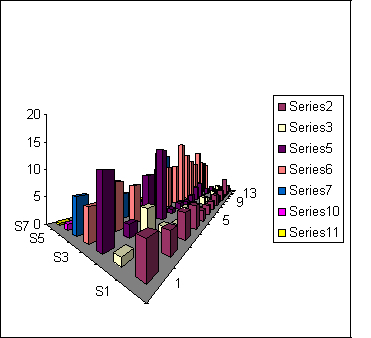
Figure 15:Exemplo de estética depauperada - gráfico de barras em 3D com dadoos obscuros.
Ferramentas técnicas do curso¶
Neste curso, trabalharemos essencialmente com Python 3.x como a linguagem de programação básica e com uma diversidade de pacotes para construção de plotagens e utilidades. A forma recomendada de prosseguir com a instalação das ferramentas é criando um ambiente virtual conda a partir do arquivo de configurações disponibilizado pelo professor e trabalhar as tarefas como um projeto de desenvolvimento.
Criação do novo ambiente¶
Para criar um ambiente mínimo para o curso, execute o comando:
conda env create --file dataviz.yml# "dataviz.yml" é um arquivo-modelo YAML para construir o ambiente "dataviz".
# Para a sua correta execução, é necessário que a variável de ambiente "CONDA_PREFIX" seja configurada
# para apontar para o diretório padrão físico em seu computador onde "dataviz" será criado.
name: dataviz
channels:
- anaconda
- conda-forge
- defaults
dependencies:
- python=3.13
- numpy
- pandas
- matplotlib
- seaborn
- plotly
- scipy
- dash
- h5py
- statsmodels
- geopandas
- networkx
- pip
- pip:
- matplotlib-venn
- xhtml2pdf
- reportlab
prefix: ${CONDA_PREFIX}/datavizPor fim, habilite o ambiente:
conda activate datavizAs dependências constituem pacotes essenciais para carregamento, limpeza, análise e visualização de uma enorme gama de dados. O resumo de cada um pode ser rapidamente localizado na internet. Os pacotes mais básicos para análise e visualização de dados são numpy, para manipulação de arrays e computação vetorizada, pandas, para manipulação de séries e datasets, e matplotlib, para plotagem estática de dados. Os demais são utilizados para tarefas especializadas. seaborn é útil para análise exploratória de dados e para visualização de dados estatísticos. plotly serve para propósitos de visualização interativa. scipy é um pacote de computação científica, com diversos métodos numéricos. h5py manipula arquivos no formato HDF5 (Hierarchical Data Format), bastante utilizados em visualização científica e armazenamento de grandes estruturas de dados. dash é uma API para construção de dashboards. geopandas suportam a visualização de dados geográficos. networkx oferece meios de plotagem de grafos e de redes complexas. matplotlib-venn gera diagramas de Venn. xhtml2pdf e reportlab são dedicados à manipulação de PDFs e úteis para geração de relatórios.
O ferramental Python disponível para visualização de dados é bastante vasto. Já existem hoje muitos outros pacotes baseados na linguagem para trabalhar com big data multipropósito (e.g. polars, hvplot, datashader, xarray, dask etc.) e cada um possui pontos positivos e negativos. Em sua atividade profissional, uma ferramenta poderá ser mais adequada do que outra e será você quem dará o veredito final.
Para manter uma linha mínima de ação no escopo técnico, neste curso utilizaremos numpy, pandas, matplotlib e seaborn para a visualização estática de dados, e plotly para a visualização interativa. Os demais pacotes serão utilizados sob demanda ao discutirmos aplicações e exemplos mais elaborados.
Exemplo aplicado¶
O código abaixo usa comandos do pandas, matplotlib e seaborn para produzir um tipo de plot conhecido em Estatística como boxplot agrupado para visualizarmos a variação do preço por litro, em R$, de 6 tipos de combustíveis comercializados no estado da Paraíba por 8 operadoras durante o primeiro semestre de 2022.
Para a plotagem, usamos parte do dataset correspondente disponibilizado pela ANP no portal Dados Abertos do Governo Federal.
Source
from pandas import read_csv
from matplotlib.pyplot import subplots
import seaborn as sns
# pandas
df = read_csv('../data/preco-combs-pb-2022-02.csv', skiprows=8)
# matplotlib
fig, ax = subplots(figsize=(14,5))
ax.set_title('Preço de combustíveis - PB - Semestre 2022/01. Fonte: ANP')
ax.set_ylabel('litro (R$)')
# seaborn
sns.set_style("whitegrid")
g = sns.boxplot(data=df, x="Bandeira", y="Valor de Venda",
hue='Produto',palette="deep",ax = ax)
sns.move_legend(g, "upper center", title='', ncol=1,
frameon=True, bbox_to_anchor=(1.11, .8))
sns.despine(offset=5,trim=True)
sns.set_style()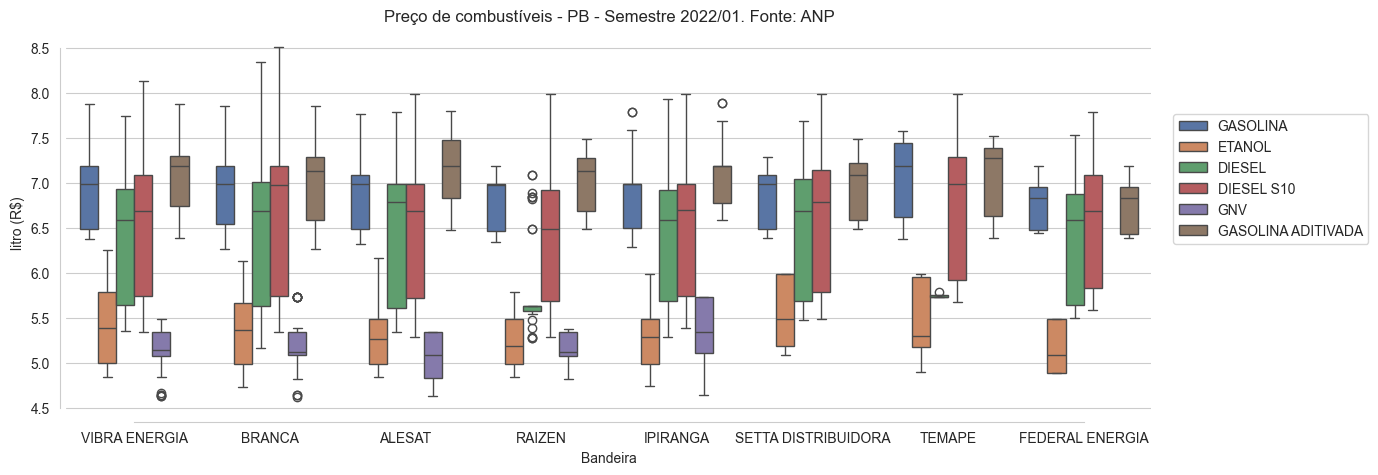
Terminologias¶
Qualquer campo do conhecimento científico é dotado de conceitos, definições, taxonomias e glossários, constituindo terminologias próprias. Em visualização de dados, pelo fato de muitos termos procederem da língua inglesa, suas traduções para a língua portuguesa podem gerar sinonímia confusa. A fim de evitar percalços semânticos, utilizaremos, neste curso, alguns termos próprios (embora não desvinculados do uso comum) separados em diferentes grupos.
Termos para pessoas¶
Storyteller: você, que está construindo o produto de visualização (cf. visualiser, analyst, visualist, designer).
Viewer: a pessoa que visualiza o produto construído (cf. consumer, reader, user).
Audiência: um grupo de espectadores ou coorte social a quem o produto de visualização é direcionado (cf. audience).
Termos para dados¶
Dado bruto: estado inicial de um dado coletado, recebido ou baixado de um repositório ainda não tratado ou sujeito a análises (cf. raw data).
Fonte: origem do dado bruto utilizado para a visualização (cf. data source).
Dataset: uma tabela ou coleção de tabelas dispostas como um array computacional e organizadas em linhas (registros, instâncias ou itens) e colunas (variáveis, detalhes dos itens).
Tipo: a especificação de uma variável de tabela. Geralmente, um dado é ordinal (obedece a uma relação de ordem), numérico (manipulável por operações aritméticas) ou categórico (identificado por um atributo que o difere de outro).
Série: sequência de valores assumidos por uma mesma variável em um dataset.
Curiosidade
A taxonomia de dados para fins de visualização da informação proposta por Ben Schneiderman em seu artigo científico The eyes have it: a task by data type taxonomy for information visualizations, de 1996, oferece 7 tipos de dados: unidimensional, bidimensional, tridimensional, temporal, multidimensional, árvore e rede. Uma versão em PDF está disponível na página do autor.
Termos para visualização¶
Projeto de visualização: conjunto de etapas progressivas que culminam na geração de um produto de visualização.
Produto de visualização: entregável de um projeto de visualização. Em geral, será uma representação visual de dados.
Representação visual de dados: termo genérico que abrange as diversas formas de disposição visual de dados, que chamaremos de plot. Um plot pode ser um traçado representativo de uma quantitidade matemática univariada (gráfico), ou a aplicação de figuras geométricas planas ou espaciais, ou ainda a impressão de formas e símbolos para fins quantitativos ou qualitativos em várias dimensões. Assim, plots incorporarão diagramas, fluxogramas, dendrogramas, superfícies, dispersões, correlações, mapas etc.
Outlier: valores em uma representação visual que escapam do intervalo normal e chamam atenção do espectador por serem ou muito menores ou muito maiores do que o esperado.
Curiosidade
Na língua inglesa, chart, graph e plot são considerados sinônimos, apesar de serem encontrados em contextos distintos. O gráfico de barras, por exemplo, é comumente chamado de bar chart e não de bar graph. Todavia, chart e graph são ambos costumeiramente traduzidos para português como “gráfico”. Além disso, graph também é traduzido como “grafo”, um conceito matemático que destoa da simples aplicação à visualização. O _gráfico de dispersão é outro exemplo que causa imprecisão semântica, visto que, em inglês, ele é conhecido como scatter plot e não como scatter graph. Enquanto algumas representações possuem traduções imediatas, isto não é o caso para outras. Por esta razão, usar plot, ou plotagem, como hiperônimo para todas as representações discutidas neste curso é uma escolha justificada. Discussões sobre diferenças desses termos em inglês podem ser encontradas aqui e aqui.
Marcos históricos da visualização de dados¶
Mapear os fatos históricos de uma determinada área da ciência de forma meticulosa é uma tarefa quase impossível. Neste capítulo, faremos um breve resumo dos principais eventos que marcaram época no desenvolvimento da visualização de dados. O material baseia-se em um capítulo escrito por Michael Friendly 6, Professor da Universidade de York, Canadá.
Registros da informação quantitativa técnica mais especializada são conhecidos desde o século XV (Figure 16), principalmente motivados pela cartografia e pelo pensamento estatístico. Entretanto, os relatos são incompletos e organizados em obras de autores fortemente ligados à matemática, astronomia e estatística. Na presente cronologia, consideramos apenas eventos ocorridos a partir do século XVII.
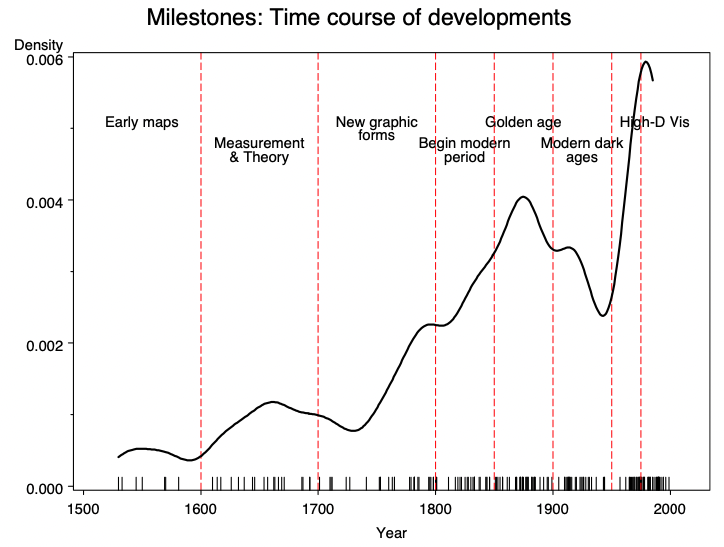
Figure 16:Marcos históricos da dataviz.
Período de 1600 - 1699¶
No início deste século, preponderou o interesse em medir quantidades físicas, tais como tempo, distância e espaço, para finalidades de navegação, expansão territorial e estudo dos astros. Vimos a ascensão da geometria analítica, da teoria dos erros e estimações, da teoria da probabilidade e da estatística demográfica. Um nome que ressalta desta época é Michael Florent van Langren, astrônomo da corte espanhola que supostamente foi quem criou a primeira representação visual de dados estatísticos em 1644 (Figure 17).
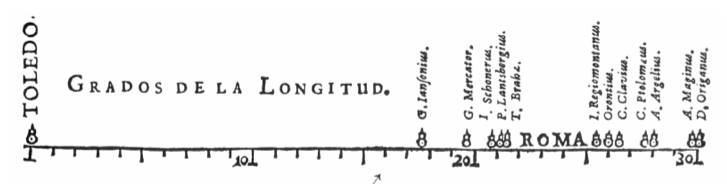
Figure 17:Gráfico de van Langren (1644) para determinação de distância, em longitude, da cidade de Toledo a Roma.
Período de 1700 - 1799¶
Durante o século XVIII, formas gráficas mais elaboradas passaram a enriquecer os mapas até então conhecidos. Caminhos foram abertos para isolinhas e isocontornos, mapeamento temático de dados físicos, geológicos, econômicos e médicos. Gráficos abstratos e os primeiros gráficos de funções matemáticas foram introduzidos, bem como novas formas visuais que “falavam por si”.
William Playfair (1759 - 1823) é considerado o principal inventor da época e o pioneiro da construção das representações visuais que utilizamos até hoje, tais como o gráfico de linhas e de barras (1786), o de setores (“pizza”) e circular (1801).
Período de 1800 - 1850¶
No curso da primeira metade deste século explodiram os gráficos estatísticos e os mapas temáticos modernos a uma taxa de produção sem precedentes, tais como histogramas, séries temporais, gráficos de dispersão e atlas compreensivos. Diversas formas de simbolismo em tópicos econômicos, sociais, morais, entre outros, progrediram em massa. Um autor proeminente desta época é Charles Minard (1781 - 1870).
Período de 1850 - 1900¶
Na segunda metade do século XIX, o cenário já estava pronto para que os mecanismos para visualização de dados se consolidassem. Escritórios oficiais sobre análises estatísticas foram estabelecidos por toda a Europa em resposta ao reconhecimento da relevância da informação numérica para ações de planejamento social, comercial e de mobilidade. A teoria estatística encabeçada por Gauss e Laplace foram responsáveis por difundir grandes quantidades de dados, fazendo com que este período fosse conhecido como a era de ouro dos gráficos estatísticos.
Período de 1900 - 1950¶
Houve pouca inovação neste período para os gráficos estatísticos, que foram ofuscados pelo crescimento dos modelos formais. As figuras passaram a ser meras ilustrações. Opostamente ao período anterior, esta fase da história da visualização de dados ficou conhecida como a era das trevas. Apesar disso, neste período as representações visuais tornaram-se populares, passando a compor livros didáticos, currículos escolares. Elas também instauraram o padrão visual em instituições governamentais, comerciais e científicas.
Período de 1950 - 1975¶
O espírito numérico e formal estabelecido em meados da década de 1930 induziu o renascimento da visualização de dados por volta de 1960. Os desenvolvimentos mais significativos responsáveis por reanimar a área após cerca de 50 anos de apatia foram os seguintes:
Nos EUA, John Tukey (1915 - 2000) configura-se como patrono da Análise Exploratória de Dados. Além de atuar em outras frentes, foi durante o trabalho com John von Neumann que Tukey introduziu o termo bit como designador de binary digit (dígito binário).
Na França, Jacques Bertin (1918 - 2010) publicou a conhecida obra Sémiologie Graphique (Semiologia Gráfica) em 1967, onde estabeleceu as variáveis visuais estruturantes para se construir imagens gráficas. As 8 variáveis de Bertin revolucionaram a ciência da percepção visual.
O desenvolvimento da computação permitiu que gráficos de alta resolução pudessem ser elaborados. Ao mesmo tempo, evoluções paralelas ocorreram, tais como o desenvolvimento de linguagens de programação no Bell Labs, da análise exploratória de dados, da tecnologia de impressão e de periféricos (plotters, terminais gráficos, mouse etc.). Esse encadeamento de fatos implicaram em novos paradigmas de expressão de ideias estatísticas e técnicas avançadas de implementação de visualização de dados.
Período de 1975 em diante¶
No final do século XX, a ciência multidisciplinar intermediou o florescimento da visualização de dados. Métodos computacionais hoje estão disponíveis para qualquer sistema operacional, preferidos por cientistas e analistas provenientes das mais diversas áreas de conhecimento. Alguns pontos de destaque são:
Desenvolvimento de sistemas interativos;
Novos paradigmas de manipulação de dados;
Métodos inovadores para representação multidimensional de dados;
Reinvenção de técnicas gráficas para dados discretos e categóricos;
Visualização de dados suportada por estruturas de dados de alta complexidade;
Domínio de conhecimento sobre aspectos cognitivos e de percepção da representação de dados;
Crescimento da infraestrutura tecnológica e computacional para visualização (códigos abertos, engenharia de software gráficos, computação paralela, streaming de dados em tempo real).
Fatos emblemáticos¶
A seguinte tabela mostra uma cronologia breve sobre fatos emblemáticos da dataviz.
| Período | Evento |
|---|---|
| 1750 - 1800 | William Playfair produz os primeiros gráficos modernos. |
| 1858 | Florence Nightingale cria o seu “diagrama Coxcomb” (circular) para ilustrar frações de mortalidade por doenças no exército britânico. |
| 1861 | Charles Minard publica a Carte Figurative. |
| 1914 | Willard Brinton publica o primeiro livro sobre visualização para negócios: Graphic Methods for Presenting Facts. |
| 1952 | Mary Eleanor Spear publica Charting Statistics, um livro de melhores práticas de criação de gráficos. |
| 1967 | Jacques Bertin publica Sémiologie Graphique. |
| 1970 - 1980 | John Tukey inaugura a visualização de dados por meio de computadores e populariza os conceito de análise exploratória de dados. |
| 1983 | Edward Tufte publica The Visual Display of Quantitative Information. |
| 1984 | William Cleveland e Robert McGill publicam o primeiro de vários trabalhos de pesquisa que tentam medir a “percepção gráfica”. |
| 1986 | Jock Mackinlay publica uma influente tese de doutorado que levou o trabalho de Jacques Bertin para a era digital. |
| 1990 - 2000 | Abordagens divergentes surgem entre agentes da visualização científica de dados e jornalistas orientados por design. |
| 2010 | Dataviz torna-se democrática por causa da internet. |
| Hoje | Dataviz se expande por um amplo espectro de disciplinas com gráficos dinâmicos e alta interatividade. |
Cronologia gráfica¶
Carte Figurative de Charles J. Minard (1781 - 1870). Versões (Figure 18, Figure 19). Ver 7.

Figure 18:Carte Figurative de Minard: ilustra a campanha militar de 1812 de Napoleão Bonaparte. Original: ENPC, Multimedia Library
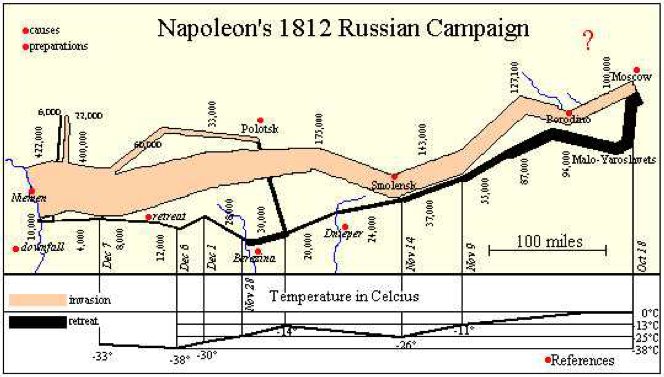
Figure 19:Carte Figurative de Minard: ilustra a campanha militar de 1812 de Napoleão Bonaparte. Revisão: Friendly, M.
Gráficos de William Playfair (1759 - 1823) sobre a economia da Inglaterra (Figure 20, Figure 21, Figure 22), disponíveis aqui.
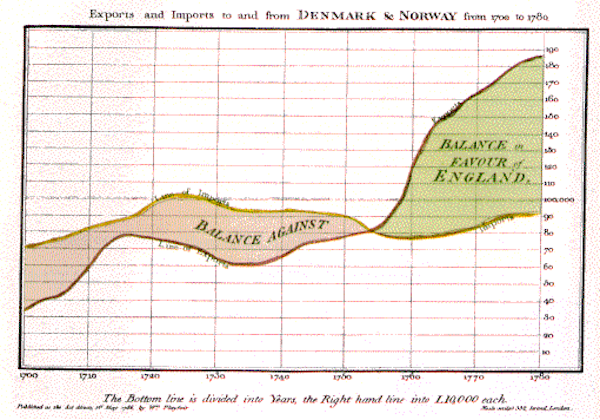
Figure 20:Balança comercial da Inglaterra.
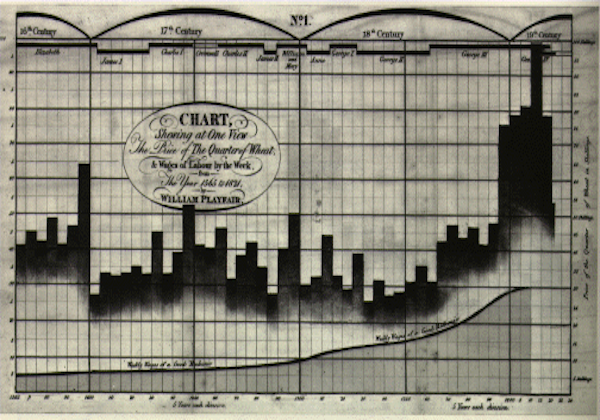
Figure 21:Série temporal tripla: variação de preço do trigo, do salário semanal e do monarca reinante ao longo de 250 anos (1565 - 1820).
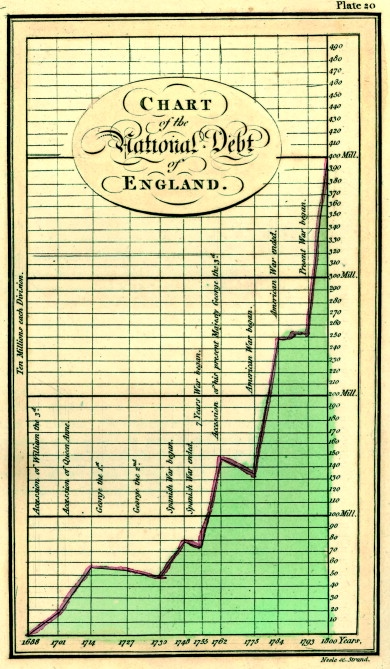
Figure 22:Dívida pública inglesa.
Gráfico circular (“coxcomb”) de Florence Nightingale (1820 - 1910) sobre causas de mortalidade no exército britânico (Figure 23, Figure 24), disponíveis aqui.
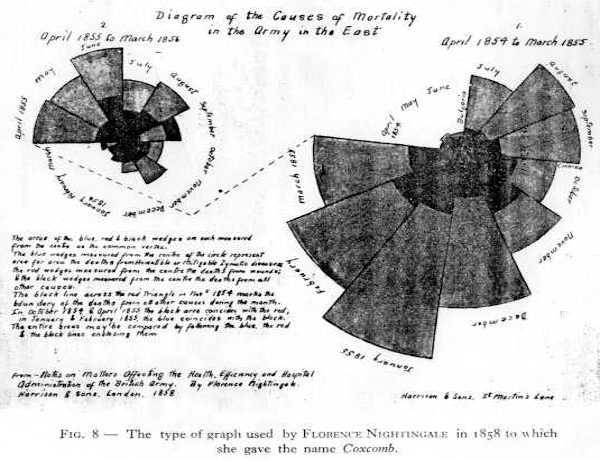
Figure 23:Gráfico circular (“coxcomb”) - original de 1858. Nightingale, enfermeira no exército britânico descobriu que a mortalidade das tropas era causada principalmente por fatores não ligados às batalhas.
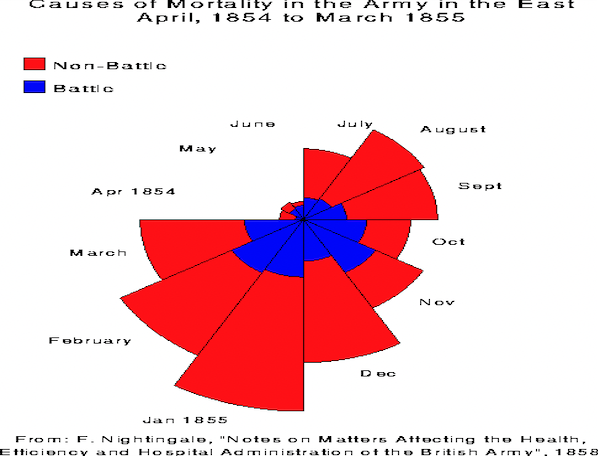
Figure 24:Gráfico circular (“coxcomb”) - reconstrução.
Links recomendados¶
- Kirk, A. (2016). Data visualisation: A handbook for data driven design. Sage.
- Wilke, C. O. (2019). Fundamentals of data visualization: a primer on making informative and compelling figures. O’Reilly Media.
- Berinato, S. (2019). The Harvard Business Review Good Charts Collection: Tips, tools, and exercises for creating powerful data visualizations. Harvard Business Press.
- Tufte, E. R. (1985). The visual display of quantitative information. The Journal for Healthcare Quality (JHQ), 7(3), 15.
- Tufte, E. R., Goeler, N. H., & Benson, R. (1990). Envisioning information (Vol. 126). Graphics press Cheshire, CT.
- Friendly, M. (2005). Milestones in the History of Data Visualization: A Case Study in Statistical Historiography. In C. Weihs & W. Gaul (Eds.), Classification: The Ubiquitous Challenge (pp. 34–52). Springer. https://www.datavis.ca/papers/gfkl.pdf
- Friendly, M. (2002). Visions and re-visions of Charles Joseph Minard. Journal of Educational and Behavioral Statistics, 27(1), 31–51.