"Toda investigação cifra-se numa proporção comparativa fácil ou difícil. Eis a razão porque o infinito enquanto infinito, por subtrair-se a toda e qualquer proporção, é desconhecido." (Nicolau de Cusa, De Docta Ignorantia, 1440)
Objetivos de aprendizagem¶
Compreender a representação numérica em computadores, o sistema de ponto flutuante e os limites impostos pela finitude dos sistemas computacionais;
Reconhecer situações de overflow, underflow, perda de precisão e outros casos especiais de operações numéricas;
Analisar os diferentes tipos de erros computacionais e suas implicações na robustez e confiabilidade de algoritmos.
Do Contínuo ao Computável: Discretização e Erros Numéricos¶
Os computadores, em sua essência, operam sobre representações discretas e finitas da informação. Diferente do mundo físico e das formulações matemáticas clássicas, as quais, na maioria das vezes, pressupõem um universo contínuo e infinitamente preciso, os sistemas computacionais lidam com números armazenados em memória finita, com quantidade limitada de dígitos binários. Esse contraste entre o mundo contínuo e o mundo discreto estabelece a base para compreender os desafios e limitações presentes na implementação de modelos matemáticos por meio de algoritmos.
Quando resolvemos numericamente problemas formulados na linguagem do Cálculo — que envolve conceitos como continuidade, derivadas e integrais —, precisamos realizar um processo chamado discretização. Esse processo consiste em transformar variáveis, domínios e operações contínuas em versões finitas e manipuláveis por algoritmos. Contudo, essa transformação introduz inevitavelmente erros computacionais, que podem ser classificados em diversas categorias: erros de arredondamento, decorrentes da representação finita dos números; erros de truncamento, provenientes da aproximação de processos infinitos (como séries ou integrais) por expressões finitas; e erros algorítmicos ou de método, que surgem das escolhas específicas dos procedimentos numéricos adotados.
Compreender a origem, o comportamento e os impactos desses erros é fundamental para qualquer profissional que utiliza simulações numéricas ou algoritmos computacionais. Mais do que uma questão técnica, essa compreensão permite avaliar a confiabilidade dos resultados, projetar métodos mais robustos e, quando possível, minimizar os efeitos adversos da discretização. Em última análise, o estudo dos métodos numéricos é, em grande parte, um estudo sobre como transpor, com inteligência e controle, a fronteira que separa o contínuo idealizado da matemática do discreto real dos computadores.
Aritmética computacional¶
Computadores representam números inteiros de forma exata [Recorte 9: Aritmética exata e números racionais]. No entanto, a representação de números reais é sempre aproximada e limitada a um conjunto finito de valores. Essa limitação decorre da necessidade de codificar números contínuos em uma estrutura binária finita. A aritmética computacional, portanto, lida tanto com números inteiros quanto com os chamados números em ponto flutuante, que permitem representar aproximações de números reais.
O estudo da aritmética computacional concentra-se em dois aspectos fundamentais:
a representação dos números no formato de máquina, isto é, em base binária, com precisão e alcance finitos; e
o desenvolvimento de algoritmos capazes de realizar operações aritméticas fundamentais, como adição, subtração, multiplicação e divisão, de forma eficiente e consistente dentro dos limites impostos pelo hardware.
Métodos numéricos são, essencialmente, algoritmos que utilizam essas quatro operações como blocos fundamentais, aplicando-as de forma estruturada e sofisticada para resolver problemas matemáticos de interesse científico e de engenharia. Atualmente, o padrão IEEE 754 [Recorte 3: Padrão de Ponto Flutuante IEEE 754] é adotado globalmente pelos fabricantes de processadores. Esse padrão define as regras para a representação, as operações e os comportamentos dos números em ponto flutuante, assegurando portabilidade e previsibilidade dos cálculos entre diferentes arquiteturas, seja em 16, 32, 64 ou 128 bits. Sua primeira versão foi publicada em 1985, com a atualização mais recente ocorrendo em 2019 1.
Unidade Lógica e Aritmética¶
A Unidade Lógica e Aritmética (ULA) é a parte do hardware computacional conectada à unidade central de processamento (CPU) que realiza as operações aritméticas e lógicas sobre os dados processados (Figura 1). A ULA é um componente eletrônico que funciona segundo a lógica dos cicuitos digitais, ou seja, interpretando operações em lógica Booleana (and, or, not).
Há muito mais por trás das operações fundamentais executadas pelos computadores. Em Python, por exemplo, há casos de aproximações que chegam a ser curiosos. Isto ocorre devido ao erro inerente da representação numérica, principalmente quando os números são fracionários.

Figure 1:Ilustração de um chip de computador destacando as interconexões responsáveis por operações lógicas, aritméticas e troca de informação com a unidade de controle.
Casos curiosos¶
A aritmética de ponto flutuante possui situações inusitadas e respostas estranhas que podem levar-nos a duvidar se estamos realizando operações corretamente. Abaixo, mostramos alguns casos curiosos (coloquialmentem) que ocorrem devido à representação finita de números pelo computador. Outras indagações sobre ponto flutuante são respondidas em [Números em ponto flutuante e seus problemas].
A fração é uma dízima. O seu triplo é?
1/30.33333333333333331/3 + 1/3 + 1/31.0A soma difere de 0.9.
0.3 + 0.3 + 0.30.89999999999999991/10 + 1/10 + 1/10 == 3/10FalseMultiplicação por fracionários
# note a variabilidade de dígitos após o ponto
for x in [0.3, 0.33, 0.333, 0.3333, 0.33333, 0.333333, 0.3333333, 0.333333333]:
print(f'3*{x}'.ljust(13,' '),'=', 3*x, sep=' ')3*0.3 = 0.8999999999999999
3*0.33 = 0.99
3*0.333 = 0.9990000000000001
3*0.3333 = 0.9999
3*0.33333 = 0.99999
3*0.333333 = 0.999999
3*0.3333333 = 0.9999998999999999
3*0.333333333 = 0.999999999
A finitude explicada¶
Os casos acima possuem uma razão comum: a capacidade finita dos computadores para representar números fracionários. Vamos analisar de modo breve o caso da fração 1/10 sem nos aprofundar em detalhes.
Em um computador de arquitetura 64 bits que segue o padrão IEEE 754, a melhor aproximação para 1/10 é um número com 55 dígitos decimais.
# imprime número com 55 dígitos
print(format(0.1,'.55f'))0.1000000000000000055511151231257827021181583404541015625
Notemos que tentar aumentar os dígitos não produzirá significância:
# imprime número com 60 dígitos
print(format(0.1,'.60f'))0.100000000000000005551115123125782702118158340454101562500000
# imprime número com 80 dígitos
print(format(0.1,'.80f'))0.10000000000000000555111512312578270211815834045410156250000000000000000000000000
Portanto, quando somamos 1/10 + 1/10 + 1/10 vemos um número diferente de 3/10.
# imprime número com 55 dígitos
print(format(0.1 + 0.1 + 0.1,'.55f'))0.3000000000000000444089209850062616169452667236328125000
Notação científica¶
Números em ponto flutuante são a versão computacional da notação científica. Escrevemos um número decimal em notação científica da seguinte forma:
com a fração (ou mantissa) determinando a precisão e o expoente a ordem de grandeza. Pontos flutuantes admitem na forma normalizada, isto é, menor do que 1. A tabela abaixo mostra alguns exemplos de como usamos essas notações.
| Número decimal | Notação científica | Repr. ponto flutuante |
|---|---|---|
| 2.65 | ||
| 0.0000012 | ||
| 4532 |
Em termos de código Python – e em outras linguagen smte, a notação científica em base 10 pode ser realizada da seguinte forma:
2.65e0, 1.2e-6, 4532e3(2.65, 1.2e-06, 4532000.0)Ponto flutuante: a reta “perfurada”¶
Desde os primórdios dos computadores mecânicos e eletrônicos, a precisão e a confiabilidade dos cálculos têm estado no centro das atenções e ambas são afetadas pelas discrepâncias entre números reais, infinitos e contínuos, e suas representações em máquina, finitas e discretas. Nas décadas de 1940 e 1950, houve uma clara percepção de que o sistema de ponto fixo, até então utilizado, era bastante limitado para dar precisão aos cálculos e que o aparato de hardware disponível na época era incapaz de lidar com situações de “sobrecarga” (overflow) ou “subfluxo” (underflow). Em outras palavras, representar números muito pequenos ou muito grandes, como 10-30 ou 543.6713, era algo impensável.
Com a introdução da aritmética de ponto flutuante nos anos 1950 e 1960, os computadores passaram a representar uma quantidade significativa de números. Porém, o preço que se pagou por esse progresso foi a aparição de novos tipos de erros, como os erros de arredondamento, que ocorrem quando os números são aproximados para caber no formato de ponto flutuante. Mesmo com a implantação do padrão IEEE-754 em 1985, o qual uniformizou a representação e a manipulação de números em ponto flutuante, os erros inerentes não foram eliminados. A pesquisa em computação científica e de alto desempenho, reveladora de que os erros são obstinados, está bastante ativa e expandindo o conhecimento. Recentemente, um grupo de espanhois trouxe perspectivas promissoras para o formato posit64 2, uma alternativa potencialmente superior ao padrão IEEE-754. Através de diversos testes, eles concluíram que o sistema baseado na arquitetura RISC-V (quinta geração da Reduced Instruction Set Computer), oferece maior precisão, resiliência a erros de arredondamento e eficiência de armazenamento.
Em vez de operar sobre o conjunto dos números reais (conjunto ), a matemática computacional está definida no domínio , o conjunto dos números em ponto flutuante representáveis pela máquina. Vejamos um exemplo.
Um sistema de ponto flutuante simplório em base binária, com apenas 3 dígitos de precisão e limites de underflow e overflow com expoentes variando de -1 a 2 possui 32 números representáveis, além do zero. Os 16 números positivos, derivados das mantissas 0.100, 0.101, 0.110 e 0.111, são os seguintes:
(...)
Prosseguindo para os números restantes, obtemos a seguinte tabela:
| m | 0.100 | 0.101 | 0.110 | 0.111 | |
|---|---|---|---|---|---|
| e | |||||
| -1 | 1/4 | 5/16 | 3/8 | 7/16 | |
| 0 | 1/2 | 5/8 | 3/4 | 7/8 | |
| 1 | 1 | 5/4 | 3/2 | 7/4 | |
| 2 | 2 | 5/2 | 3 | 7/2 |
Na reta real, esses valores ficariam dispostos da seguinte forma:

Isto é, é uma reta “perfurada”, para a qual apenas 16 números positivos, 16 simétricos destes (que seriam refletidos na origem para o extremo negativo) e mais o 0 são representáveis. Logo, esse sistema seria capaz de representar apenas 33 números.
Simulador de ¶
Clássicamente, um sistema de ponto flutuante é descrito por , onde é a base (geralmente binária nos sistemas modernos), são os dígitos significativos da mantissa, que determina a precisão, é o menor expoente inteiro possível (que controal o limite de underflow) e é o maior expoente inteiro possível (que controla o limite de overflow). No exemplo acima, o sistema é .
O código abaixa gera uma reta perfurada para um sistema computacional de interesse.
Source
import numpy as np
import matplotlib.pyplot as plt
def simulacao_F(b,t,L,U):
x = []
epsm = b**(1-t) # epsilon de máquina
M = np.arange(1.,b-epsm,epsm)
E = 1
for e in range(0,U+1):
x = np.concatenate([x,M*E])
E *= b
E = b**(-1)
y = []
for e in range(-1,L-1,-1):
y = np.concatenate([y,M*E])
E /= b
yy = np.asarray(y)
xx = np.asarray(x)
x = np.concatenate([yy,np.array([0.]),xx])
return x
Y = simulacao_F(2,4,-3,5)
X = np.zeros(Y.shape)
# plotagem
fig, ax = subplots(figsize=(8,1),constrained_layout=True)
ax.scatter(Y,X,marker='o',color='g');
ax.get_yaxis().set_visible(False)

Limites de máquina para ponto flutuante¶
Nos sistemas mais modernos, os parâmetros de crescem vertiginosamente com o aumento dos bits (Tabela 1). A quantidade de números representáveis no Float64 é aproximadamente 1.84e19 apenas considerando os números normais.
Table 1:Parâmetros de para as arquiteturas modernas.
| Formato | Base () | Dígitos significativos () | Expoente inferior () | Expoente superior () |
|---|---|---|---|---|
| float16 | 2 | 11 | -14 | +15 |
| float32 | 2 | 24 | -126 | +127 |
| float64 | 2 | 53 | -1022 | +1023 |
| float128 (*) | 2 | 113 | -16382 | +16383 |
(*) Nem todos os processadores oferecem suporte nativo para float128. É frequentemente implementado em software.
Em Python, podemos utilizar diferentes sistemas de ponto flutuante. Cada um possui suas particularidades. Os mais comuns são:
float16(meia precisão): ideal para aplicações onde a velocidade e o uso de memória são críticos, como em inferências de aprendizado profundo em dispositivos com recursos limitados.float32(precisão simples): comumente usado em jogos, gráficos, e muitas aplicações de aprendizado de máquina devido ao bom equilíbrio entre precisão e eficiência.float64(precisão dupla; alias parafloat): essencial para simulações científicas, finanças e outras áreas onde a precisão é crucial e a memória não é preocupação.
O numpy suporta todos os três na maioria dos computadores de hoje (Tabela 2).
Table 2:Comparativo entre sistemas de ponto flutuante
| Atributo | float16 | float32 | float64 |
|---|---|---|---|
| Tamanho | 16 bits (2 bytes) | 32 bits (4 bytes) | 64 bits (8 bytes) |
| Precisão | Baixa | Moderada | Alta |
| Intervalo de Valores | a | a | a |
| Bits de Sinal | 1 | 1 | 1 |
| Bits de Expoente | 5 | 8 | 11 |
| Bits de Mantissa | 10 | 23 | 52 |
| Uso de Memória | Muito baixo | Moderado | Alto |
| Aplicações | Aprendizado profundo em dispositivos de recursos limitados | Gráficos de computador, simulações científicas, aprendizado de máquina | Cálculos científicos, engenharia, finanças de alta precisão |
| Exemplo de Valores | 3.140625 para representar aproximadamente | 3.1415927 para representar aproximadamente | 3.141592653589793 para representar aproximadamente |
| Vantagens | Usa menos memória e é mais rápido em termos de computação. Ideal para aplicações onde a memória é restrita e a precisão pode ser sacrificada. | Oferece um bom equilíbrio entre precisão e uso de memória. Amplamente utilizado em gráficos e aprendizado de máquina. | Alta precisão e amplo intervalo dinâmico. Ideal para cálculos científicos e de engenharia onde a precisão é crucial. |
| Desvantagens | Precisão muito limitada, o que pode levar a erros significativos em cálculos complexos. | Pode não ser suficientemente preciso para cálculos científicos muito precisos. | Usa mais memória e pode ser mais lento em termos de computação comparado com float16 e float32. |
A seguinte função imprime os valores dos principais atributos de numpy.finfo que nos ajudam a entender melhor os limites de máquina em Python para esses sistemas de ponto flutuante.
Source
import numpy as np
def print_attribute(dtype: str, attrib: str) -> None:
"""
Imprime informações de atributo para os sistemas de ponto flutuante \
de 16, 32 e 64 bits operados pelo numpy
Atributos relevantes:
- eps: menor valor x, tal que 1.0 + x > 1.0 (epsilon de máquina)
- max: maior número finito que pode ser representado pelo tipo de dado de ponto flutuante.
- min: menor número finito negativo que pode ser representado pelo tipo de dado de ponto flutuante.
- tiny: menor número positivo normalizado que pode ser representado.
- nexp: número de bits no expoente
- nmant: número de bits na mantissa
"""
# checagem de sistema permitido
assert dtype in ['float16', 'float32', 'float64'], 'Sistema não permitido!'
# impressão
print(f'{attrib}:')
exec(f'print(np.finfo(np.{dtype}).{attrib})')A partir daí, podemos verificar os valores para cada sistema individualmente:
print('--- float16 \n')
for attrib in ['eps', 'max', 'min', 'tiny', 'nexp', 'nmant']:
print_attribute('float16', attrib)
print('\n--- float32 \n')
for attrib in ['eps', 'max', 'min', 'tiny', 'nexp', 'nmant']:
print_attribute('float32', attrib)
print('\n--- float64 (float) \n')
for attrib in ['eps', 'max', 'min', 'tiny', 'nexp', 'nmant']:
print_attribute('float64', attrib)Output
--- float16
eps:
0.000977
max:
6.55e+04
min:
-6.55e+04
tiny:
6.104e-05
nexp:
5
nmant:
10
--- float32
eps:
1.1920929e-07
max:
3.4028235e+38
min:
-3.4028235e+38
tiny:
1.1754944e-38
nexp:
8
nmant:
23
--- float64 (float)
eps:
2.220446049250313e-16
max:
1.7976931348623157e+308
min:
-1.7976931348623157e+308
tiny:
2.2250738585072014e-308
nexp:
11
nmant:
52
O épsilon de máquina¶
A unidade de arredondamento, comumente chamada de “épsilon de máquina” e aqui denotada por , é definida como o menor número positivo que, somado à unidade, produz um resultado diferente de 1 na máquina. Em termos matemáticos:
De outra forma, essa definição pode ser interpretada como: é a menor diferença entre 1 e o próximo número maior que pode ser representado no sistema numérico da máquina.
Para ilustrar este conceito, consideremos um sistema hipotético de 8 bits, no qual cada número é codificado como uma sequência de 8 dígitos binários, segundo a seguinte estrutura:
1 bit para o sinal;
3 bits para o expoente (com bias);
4 bits para a mantissa (ou parte fracionária).
Neste sistema, o número 1 em base decimal é representado pelo binário 00110000. O próximo número representável é 00110001, que corresponde ao valor decimal 1.0625. Assim, o épsilon de máquina para este sistema é:
Para este cálculo, utilizamos a fórmula geral de ponto flutuante: .
O bias, para 3 bits de expoente, é calculado como:
No caso do número 1, os bits do expoente são 011, que correspondem ao valor:
Como o sinal é positivo e a mantissa está zerada , o cálculo resulta em:
A representação binária 00110000 corresponde, portanto, ao número decimal 1.
No próximo número representável, a menor alteração ocorre no bit menos significativo da mantissa, que vale . Isso significa que a sequência binária 00110001 representa: 1 + 0.0625 = 1.0625. Portanto, . Se adicionarmos outro bit da mantissa (o segundo bit menos significativo), obteremos uma contribuição de , que somada à anterior resulta em: 0.0625 + 0.125 = 0.1875. Assim, o número subsequente seria 1.1875, e a diferença entre 1.1875 e 1.0625 é 0.125, maior que .
Esse exemplo evidencia um ponto fundamental: a unidade de arredondamento () não corresponde a uma “distância constante” na reta dos números reais. A densidade dos números representáveis na máquina não é uniforme — ela depende diretamente do valor do expoente. Assim, embora defina a menor diferença ao redor de 1, para números muito maiores ou muito menores, essa distância aumenta ou diminui exponencialmente, como a figura da reta perfurada anterior mostra.
Sensibilidade numérica¶
A sensibilidade numérica mede o quanto a saída de um problema ou algoritmo é afetada por pequenas variações na entrada. Se pequenas perturbações nos dados de entrada causam grandes variações na saída, dizemos que o problema (ou o algoritmo) é sensível, ou seja, mal condicionado. Se, ao contrário, a saída varia pouco frente a pequenas perturbações, dizemos que o problema é bem condicionado, portanto, pouco sensível.
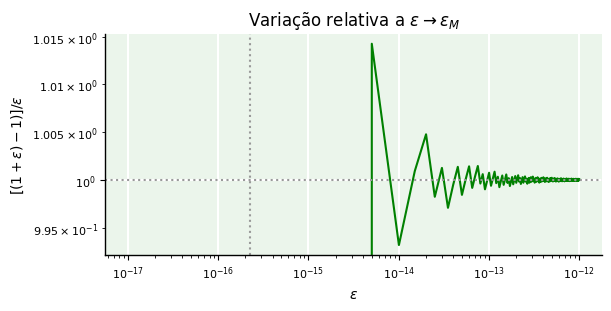
Quando subtraímos 1 de valores de cada vez menores, a subtração no denominador da fração
começa a se aproximar de zero por cancelamento subtrativo e o valor de torna-se cada vez mais instável até cair a “zero”. O efeito de em cálculos pode ser mostrado na figura abaixo.
Valores e operações especiais¶
O padrão IEEE 754 traz alguns valores especiais para representar cadeias de bits especiais. São eles:
NaN (not a number): representa um valor que é um erro.
Inf (infinity): representa o infinito (em ambos os sentidos, positivo e negativo).
A partir desses valores especiais, operáveis pelo módulo numpy com numpy.nan e numpy.inf, respectivamente, podemos imitar operações matemáticas “equivalentes”. Primeiramente, façamos:
from numpy import nan, infEm seguida, analisemos qual é o comportamento de algumas operações especiais:
2.1/inf, -4/inf, 5.2/-inf, 6/-inf(0.0, -0.0, -0.0, -0.0)inf*inf, inf*(-inf), -inf*inf, (-inf)*(-inf)(inf, -inf, -inf, inf)(neste caso, teremos um erro de divisão por zero)
1/0, -2/0, 3/(-0), 4/(-0)---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
Cell In[20], line 1
----> 1 1/0, -2/0, 3/(-0), 4/(-0)
ZeroDivisionError: division by zero1*inf, -2*inf, 3.1112*(-inf), -111*(-inf)(inf, -inf, -inf, inf)inf + inf, inf - inf, - inf + inf, -inf - inf (inf, nan, nan, -inf)(neste caso, também teremos um erro de divisão por zero)
0/-0---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
Cell In[23], line 1
----> 1 0/-0
ZeroDivisionError: division by zeroinf/inf, inf/-inf, -inf/inf, -inf/-inf(nan, nan, nan, nan)inf*0,-inf*0(nan, nan)nan == nan, nan != nan(False, True)nan + inf == nan + infFalseErros e seus efeitos¶
Credita-se a Alexander Pope (1688 - 1744), poeta inglês, a autoria do provérbio: “errar é humano; perdoar é divino” [phrases.org.uk]. Apesar de sua motivação, no século XVIII, ser o apontamento da indelével falibilidade humana – que Nicolau de Cusa (citado na epígrafe) via como elemento positivo para que a humanidade construa seu conhecimento gradativamente com percepção intelectual de sua insipiência –, esta máxima tem uma tênue relação com os diversos tipos de erros que persistem em cálculos realizados por máquinas. Discutiremos a seguir algumas definições de erros computacionais e como eles se manifestam ou se propagam em cálculos numéricos aplicáveis a qualquer área do conhecimento.

Motivação¶
Como forma de demonstrar que cômputos podem ter resultados distintos, consideremos a somatória (descendente, da maior para a menor parcela)
e a sua versão escrita de forma “refletida” (ascendente, da menor para a maior parcela), ou seja,
É evidente que e são matematicamente equivalentes e devem produzir o mesmo resultado independentemente de e do sentido em que forem somadas. Porém, vejamos o que acontece ao programarmos uma pequena função para computar ambas as formas.
from prettytable import PrettyTable as pt
# define séries
def S(n):
S_D = 0
for k in range(1,n+1):
S_D += 1/k
S_A = 0
for k in range(n,0,-1):
S_A += 1/k
# diferença
E = S_D - S_A
return S_D, S_A, E
# cria objeto para tabela
tbl = pt()
tbl.field_names = ['n','S_A(n)','S_D(n)','S_D(n) - S_A(n)']
tbl.align = 'c'
# loop de teste
for n in [10**1, 10**2, 10**3, 10**4, 10**5]:
sd, sa, e = S(n)
row = [n,sa,sd,e]
tbl.add_row(row)
# imprime tabela
print(tbl)+--------+--------------------+--------------------+------------------------+
| n | S_A(n) | S_D(n) | S_D(n) - S_A(n) |
+--------+--------------------+--------------------+------------------------+
| 10 | 2.9289682539682538 | 2.9289682539682538 | 0.0 |
| 100 | 5.1873775176396215 | 5.187377517639621 | -8.881784197001252e-16 |
| 1000 | 7.485470860550341 | 7.485470860550343 | 2.6645352591003757e-15 |
| 10000 | 9.787606036044386 | 9.787606036044348 | -3.730349362740526e-14 |
| 100000 | 12.090146129863408 | 12.090146129863335 | -7.283063041541027e-14 |
+--------+--------------------+--------------------+------------------------+
Como se percebe pela última coluna, os valores produzidos pelas somas para não são exatamente iguais. Embora existam diferenças ínfimas nos resultados, elas não são zero, assim indicando que a maneira como computamos expressões matemáticas cujos resultados são idênticos pode levar a resultados distintos. Ter-se equivale a admitir a presença de um “erro” – ainda que ele seja pequeno e desprezível – cuja magnitude depende da escolha de .
Naturalmente, se tomássemos a versão infinita de (ou ), chamando-a apenas de e substituindo por , isto é,
tanto e seriam consideradas aproximações para .
Supondo que somente é a forma correta de “chegar perto” de , a implicação
revelaria o acréscimo como uma quantidade não-nula coexistindo com o valor finito . Uma vez que computadores são incapazes de calcular somas infinitas por limitação de memória, define um tipo de erro. Este erro é inerente ao processo de cálculo aproximado de séries infinitas. Além disso, ele dependerá de , ou seja, da quantidade de termos utilizados na soma para aproximar o real valor de .
Entretanto, estamos ainda diante de um problema de difícil tratamento, visto que a soma só pode ser obtida aproximadamente, pois não é convergente. Logo, é impossível estabelecer um valor “exato” para , a fim de compará-lo com suas aproximações. Caso intentássemos medir discrepâncias no cálculo desta série, teríamos que adotar um valor já aproximado para cumprir o papel de exato e utilizar outros valores também aproximados como “aproximações de uma aproximação”. Embora pareça estranho e paradoxal, o que acontece em muitas situações práticas quando lidamos com um processo iterativo ou de aproximações sucessivas é justamente isso.
Vamos tomar os valores da tabela de . Suponhamos que assumisse o papel de valor “exato” de . Fosse este o caso, poderíamos calcular pelo menos quatro erros:
Para obter cada valor acima, poderíamos escrever:
# O valor de S_D(n) está na entrada (i,2) da tabela, para i = 0,1,2,3,4.
# Em Python, cada um é acessível por indexação na forma [i][2]
E_100000 = tbl.rows[4][2] # i = 4
E_10000 = E_100000 - tbl.rows[3][2] # i = 3
E_1000 = E_100000 - tbl.rows[2][2] # i = 2
E_100 = E_100000 - tbl.rows[1][2] # i = 1
E_10 = E_100000 - tbl.rows[0][2] # i = 0
# Impressão de valores
print(E_100000)
print(E_10000)
print(E_1000)
print(E_100)
print(E_10)12.090146129863335
2.302540093818987
4.604675269312992
6.902768612223714
9.161177875895081
Não é difícil ver que o valor de em relação a aumenta quando tomamos valores de cada vez menores. Em outras palavras, nossas aproximações de um valor supostamente exato (aproximado) tornam-se cada vez mais pobres quando não dispomos de parcelas suficientes para somar. Além disso, usar como ponto de referência não é nada confiável, já que ele apenas fará com que tenhamos uma sensação ilusória de exatidão.
Se, em vez de uma série divergente, escolhermos outra, convergente, poderemos fazer cálculos de erro tomando como referência um valor definitivamente exato. Então, consideremos a série
A série ficou conhecida como Problema de Basel, proposto em 1650 pelo matemático italiano Pietro Mengoli, e solucionado por Leonhard Euler em 1734 – Basel é o nome de uma cidade da Suíça, onde Euler nasceu. Graças a Euler e a teoria matemática operante nos bastidores, existe certeza suficiente de que .
Do mesmo modo como fizemos no caso anterior, geraremos uma nova tabela para valores de com crescente até o limite de 100.000, até porque não temos como computar ad infinitum. Então, vejamos um código similar:
from math import pi
# define série
def S2(n):
S_2 = 0
for k in range(1,n+1):
S_2 += 1/k**2
# valor exato
S_2ex = pi**2/6
# diferença
E = S_2ex - S_2
return S_2ex, S_2, E
# cria objeto para tabela
tbl2 = pt()
tbl2.field_names = ['n','S_2','S_2(n)','S_2 - S_2(n)']
tbl2.align = 'c'
# loop de teste
for n in [10**1, 10**2, 10**3, 10**4, 10**5]:
s2, s2n, e = S2(n)
row = [n,s2,s2n,e]
tbl2.add_row(row)
# imprime tabela
print(tbl2)+--------+--------------------+--------------------+-----------------------+
| n | S_2 | S_2(n) | S_2 - S_2(n) |
+--------+--------------------+--------------------+-----------------------+
| 10 | 1.6449340668482264 | 1.5497677311665408 | 0.09516633568168564 |
| 100 | 1.6449340668482264 | 1.6349839001848923 | 0.009950166663334148 |
| 1000 | 1.6449340668482264 | 1.6439345666815615 | 0.0009995001666649461 |
| 10000 | 1.6449340668482264 | 1.6448340718480652 | 9.999500016122376e-05 |
| 100000 | 1.6449340668482264 | 1.6449240668982423 | 9.999949984074163e-06 |
+--------+--------------------+--------------------+-----------------------+
Neste caso, a diferença existente na última coluna caracteriza, de fato, o erro real entre o valor exato e suas aproximações, de modo que, neste caso,
A partir daí, notamos que o erro reduz-se a quase zero à medida que o valor de aumenta, assim dando-nos uma constatação, pelo menos aproximada, de que a soma, de fato, é . Para obtermos os valores dos erros, um código similar poderia ser implementado:
# Expressões do erro real
E_100000 = pi**2/6 - tbl2.rows[4][2] # i = 4
E_10000 = pi**2/6 - tbl2.rows[3][2] # i = 3
E_1000 = pi**2/6 - tbl2.rows[2][2] # i = 2
E_100 = pi**2/6 - tbl2.rows[1][2] # i = 1
E_10 = pi**2/6 - tbl2.rows[0][2] # i = 0
# Impressão
print(E_100000)
print(E_10000)
print(E_1000)
print(E_100)
print(E_10)9.999949984074163e-06
9.999500016122376e-05
0.0009995001666649461
0.009950166663334148
0.09516633568168564
Talvez não tenha sido percebido, mas, até aqui, já tratamos, conceitualmente, de três tipificações de erro, a saber:
erro de truncamento, quando limitamos o número de termos de uma expansão infinita, tornando-a finita.
erro real aproximado (ou erro verdadeiro aproximado), quando assumimos que o valor exato da expansão infinita (série divergente) é a soma obtida até a parcela , com muito grande, mas finito, e calculamos a diferença entre este valor e a soma obtida até uma parcela anterior à -ésima;
erro real (ou erro verdadeiro), quando calculamos a diferença entre a soma exata (série convergente) e a soma obtida até a parcela .
Curioso, não? E não para por aí! Ainda há outras definições de erro. Veremos mais algumas no decorrer do curso.
Tipos de erros¶
Consideremos avaliar o polinômio no ponto .
Vamos fazer o seguinte:
Assumir que 82132.957032 seja o valor exato para o polinômio em .
Calcular utilizando duas formas.
# Código para gerar polinômio cúbico com raízes reais
from numpy import random
from sympy.abc import x, a, b, c, d
from sympy import roots, lambdify
# Semente aleatória
random.seed(1)
# Um polinômio do terceiro grau terá as 3 raízes reais e distintas
# se o discriminante for > 0. Aqui, criamos um polinômio que
# satisfaz tais condições por busca aleatória
Delta = -1
a,b,c,d = 0,0,0,0
while Delta <= 0:
A,B,C,D = random.randn(1,4)[0,:]
Delta = -27*A**2*D**2 + 18*A*B*C*D -4*A*C**3 - 4*B**3*D + B**2*C**2
a,b,c,d = A,B,C,D
# Polinômio cúbico simbólico
P3 = a*x**3 + b*x**2 + c*x + d
# Polinômio cúbico numérico
P3n = lambdify(x,P3,'numpy')
# Raízes simbólicas
r = list(roots(P3,x).keys())
r1 = r[0]
r2 = r[1]
r3 = r[2]
# Raízes numéricas com os valores encontrados
r1n = r1.subs({'a':a, 'b':b, 'c':c, 'd': d}).evalf(10)
r2n = r2.subs({'a':a, 'b':b, 'c':c, 'd': d}).evalf(10)
r3n = r3.subs({'a':a, 'b':b, 'c':c, 'd': d}).evalf(10)
#P3_ex = 0.172428207550436*x**3 - 0.877858417921372*x**2 + 0.0422137467155928*x + 0.582815213715822# Valor (comentários)
x = 79.9
# Forma padrão
Px = 0.172*x**3 - 0.878*x**2 + 0.042*x + 0.583
# Forma estruturada (Hörner)
PHx = x*(x*(0.172*x - 0.878) + 0.042) + 0.583
# Impressão
print(f'P({x}) = {Px:.14f}')
print(f'PH({x}) = {PHx:.14f}')
P(79.9) = 82132.95064800001273
PH(79.9) = 82132.95064799999818
Como se vê, a partir da 7a. casa decimal, começamos a notar uma leve diferença do valor do polinômio, embora ambas as formas, padrão de Hörner (estruturada), sejam matematicamente equivalentes. Embora os valores sejam próximos, a forma estruturada é uma opção menos custosa, sob o ponto de vista computacional, visto que ela possui menos avaliações de operações aritméticas.
A forma polinomial padrão, escrita de maneira ampliada, resulta em
ao passo que a forma de Hörner é escrita como:
Qual é a diferença entre ambas? O número de multiplicações (vermelho) e adições/subtrações (azul) é diferente. Enquanto na forma , temos 6 multiplicações e 3 adições/subtrações, a forma reduz as operações para 3 multiplicações e 3 adições/subtrações. Isso é o mesmo que dizer que o número de operações aritméticas de multiplicação foi reduzido em 50%!
A conclusão é: a avaliação de polinômios pela forma de Hörner é mais lucrativa e propensa a um erro menor.
Erro real¶
O erro real (ou verdadeiro), , não sinalizado, entre o valor exato e o aproximado é dado por:
Note que, por convenção, se , erramos por superestimação (“excesso”). Por outro lado, se , erramos por subestimação (“omissão”).
Calculamos o erro real operando com diferença simples.
Utilizando o exemplo da seção anterior, temos:
# Valor exato
Px_ex = 82132.957032
# Erro real (forma padrão)
E_P = Px - Px_ex
print(E_P)
# Erro real (forma de Hörner)
E_PH = PHx - Px_ex
print(E_PH)
-0.0063839999929768965
-0.006384000007528812
Erro absoluto¶
O erro absoluto, , é a versão sinalizada de . Dado por
ele ignora a condição de subestimação ou superestimação e se atém à diferença absoluta entre o valor exato e o valor aproximado.
A função módulo, , pode ser diretamente calculada com abs.
# Erro absoluto (forma padrão)
EA_P = abs(Px - Px_ex)
print(EA_P)
# Erro absoluto (forma de Hörner)
EA_PH = abs(PHx - Px_ex)
print(EA_PH)
0.0063839999929768965
0.006384000007528812
É evidente que . Entretanto, podemos verificar isso pelo seguinte teste lógico:
# O teste é verdadeiro
EA_PH > EA_PTrueErro relativo¶
O erro relativo, , aperfeiçoa a idea de erro absoluto a partir do momento que passa a considerar a ordem de grandeza das quantidades envolvidas, mensurando uma variação que se limita ao valor exato. Assim,
expressão que, devido à simetria da função módulo, pode ainda ser expandida para
Os erros relativos podem ser computados como:
ER_P = EA_P/abs(Px_ex)
print(ER_P)
ER_PH = EA_PH/abs(Px_ex)
print(ER_PH)7.772762875796146e-08
7.772762893513656e-08
Erro relativo percentual¶
O erro relativo percentual é outra forma útil de expressar a disparidade relativa entre valores. Ele é definido por:
Como não temos uma forma explícita de percentual, por cálculo, o melhor a fazer é algo como:
ER_Pp = ER_P * 100
print(f'{ER_Pp:e} %')
ER_PHp = ER_PH * 100
print(f'{ER_PHp:e} %')7.772763e-06 %
7.772763e-06 %
Erro relativo aproximado (benchmark)¶
Como vimos no exemplo motivacional deste capítulo, há casos (a maioria deles) em que não dispomos de valores exatos (obtidos por soluções analíticas, por exemplo), sendo possível estimar erros relativos apenas aproximadamente usando um valor de referência. Costuma-se chamar este valor de benchmark. Definido o benchmark por , o erro relativo aproximado é dado:
No exemplo da avaliação dos polinômios, se não dispuséssemos do valor exato, ou ou deveria ser adotado como benchmark. Se optássemos pelo segundo, apenas um erro relativo aproximado poderia ser calculado, a saber:
ER_ = abs(PHx - Px)/abs(PHx)
print(f'{ER_:e}')1.771751e-16
Erro relativo aproximado percentual¶
O erro relativo aproximado percentual é, meramente, a versão percentual do erro relativo aproximado, logo, dado por
Erro de cancelamento¶
O erro de cancelamento ocorre quando números de grandezas próximas são subtraídos. Como exemplo de situação crítica, induzimos uma divisão por zero usando o valor do épsilon de máquina ao fazer
Isto ocorre porque o denominador sofre um cancelamento subtrativo Uma vez que , a operação não produz efeito sobre 1, de modo que a computação encontra um “limbo”. Para a matemática exata, a operação deveria ser “diferente de zero”.
# inf
from numpy import finfo
from warnings import filterwarnings;
filterwarnings("ignore")
e = finfo(float).eps
1/(1 + 0.25*e - 1)np.float64(inf)1+0.25*e > 1np.False_Erros de truncamento e de arredondamento¶
O erro de truncamento está relacionado ao “corte” abrupto de dígitos de precisão em um valor numérico ou de parcelas em uma expansão infinita. No início do capítulo, exemplificamos como uma série pode ser aproximada truncando um ou mais termos de sua expansão.
No caso de números, o truncamento ocorre quando se ignora o valor da -ésima casa decimal para finalidades de aproximação até a -ésima casa. Por exemplo, se , a aproximação de por truncamento até a terceira casa seria . O dígito 6 é ignorado nos cálculos.
No caso do arredondamento, o -ésimo dígito é somado de 1 se o dígito da -ésima casa for maior ou igual a 5. A aproximação de por arredondamento até a terceira casa seria , visto que o dígito 6 é maior do que 5. A regra de arredondamento é a que usamos no cotidiano.
Erros e funções de perda no contexto da inteligência artificial¶
Diversas definições de erro também existem no contexto da inteligência artificial (IA). Todavia, em modelos de IA, o conceito de erro está profundamente vinculado à diferença entre a saída produzida por um modelo e um valor considerado verdadeiro, chamado de “gabarito” (ground truth). O gabarito representa o conhecimento correto sobre um fenômeno, seja a classificação correta de uma imagem, o preço real de um imóvel, ou a demanda energética observada em determinado dia. O modelo, por sua vez, gera uma saída predita — e a diferença entre predição e realidade constitui o erro.
Essa diferença é quantificada por meio de uma função de perda (loss function), que mede o quão ruim uma predição foi em relação ao gabarito. Portanto, a conotação do erro nesse contexto é de uma métrica de desempenho. Várias métricas existem e tendem a expressar distâncias entre valores reais e valores preditos. A seguir, descrevemos algumas dessas métricas sob o ponto de vista de vetores no espaço de dimensões. Em todas as fórmulas, é o vetor de dados reais, cuja -ésima componente é representada por , e é o vetor de dados preditos (aproximados), cuja -ésima componente é representada por . Assim, reflete o número de pontos de amostragem.
Erro absoluto médio¶
O erro absoluto médio (mean absolute error, MAE) é definido como:
O MAE é útil quando queremos minimizar a soma das diferenças absolutas.
Erro quadrático médio¶
O erro quadrático médio (mean squared error, MSE) é definido como:
Erro absoluto médio percentual¶
O erro absoluto médio percentual (mean absolute percentage error, MAPE) é definido como:
Erro logarítmico quadrático médio¶
O erro logarítmico quadrático médio (mean squared logarithmic error, MSLE) é definido como:
Erro induzido pela norma e erro máximo¶
O MAE e o MSE, por exemplo, são casos particulares da definição genérica dada por:
para e , respectivamente. Em particular, a chamada “norma do máximo” é definida por
que mede a maior diferença absoluta entre o vetor de valores reais e o vetor de valores preditos.
A norma é chamada de norma de Minkowski. As diferentes normas decorrentes da escolha de são usadas em contextos diferentes para medir mudanças específicas. Quanto maior é o valor de , mais ela se concentra em captar discrepâncias maiores. Assim, normas menores são mais robustas a outliers. Quando , temos a norma de Manhattan; quando , temos a norma Euclidiana, bastante conhecida de outras disciplinas.
Curiosidade - IA aplicada ao armazenamento geológico de carbono
Nos últimos anos, métodos de aprendizagem profunda vêm sendo aplicados à identificação automatizada de corpos salinos em imagens sísmicas tanto para finalidades de exploração de combustíveis fósseis, como também para armazenamento geológico de carbono. Em aplicações dessa natureza, o gabarito, em geral, é uma imagem interpretada por um geólogo profissional. Algoritmos de classificação, por sua vez, tentam delinear a mesma estrutura geológica obtida pelo humano baseando-se em métricas formuladas a partir de definições de erro como as que estudamos nesta seção. Para saber mais, veja os artigos: 3, 4 e 5.
Calculando o desempenho¶
Usando a biblioteca scikit-learn, é possível utilizar funções já disponíveis no módulo sklearn.metrics para calcular essas métricas. Abaixo, utilizamos um exemplo genérico para um conjunto de valores reais e valores preditos associados aos reais para . As plotagens resumem a dispersão entre valores reais e preditos e os erros dados por cada métrica.
from sklearn.metrics import mean_squared_error as MSE
from sklearn.metrics import mean_absolute_error as MAE
from sklearn.metrics import mean_absolute_percentage_error as MAPE
from sklearn.metrics import mean_squared_log_error as MSLE
from sklearn.metrics.pairwise import pairwise_distances as pNorm
from numpy import array
from matplotlib.pyplot import subplots
from mpl_toolkits.axes_grid1.inset_locator import inset_axes
import matplotlib.ticker as mticker
# conjunto de dados
x = array([3.0, 1.7, 4.0, 7.0]) # valores reais
xhat = array([2.8, 1.4, 3.0, 8.0]) # valores preditos
# erros
mae = MAE(x,xhat)
mse = MSE(x,xhat)
mape = MAPE(x,xhat)
msle = MSLE(x,xhat)
# normas de Minkowski
norms = []
P = [0.5, 0.8, 1.2, 4.0, 6.0, 10.0] # valores p
# calcula por matrizes de distâncias, mas armazena valor único
for p in P:
norms.append(pNorm([x],[xhat],metric='minkowski',p=p).ravel()[0])
# gráficos
fig, ax = subplots(1,3,figsize=(13,3),constrained_layout=True)
ax[0].plot(x,x,'k:',lw=1.0)
ax[0].plot(x,xhat,'og')
ax[0].set_xlabel('real'); ax[0].set_ylabel('predito')
ax[1].bar(x=['MAE','MSE','MAPE','MSLE'],height=[mae,mse,mape,msle],color='g')
ax[1].set_xlabel('métricas'); ax[1].set_ylabel('erro')
ax[2].plot(P[3:],norms[3:],'sg')
ax[2].xaxis.set_major_locator(mticker.FixedLocator(P[3:]))
ax[2].set_xticklabels(list(map(lambda x: f'p={x:.1f}',P[3:])))
# eixo embutido
axi = inset_axes(ax[2],width="50%", height="40%", loc="upper right")
axi.plot(P[:3],norms[:3],'sg')
axi.xaxis.set_major_locator(mticker.FixedLocator(P[:3]))
axi.set_xticklabels(list(map(lambda x: f'p={x:.1f}',P[:3])))
ax[2].set_xlabel('normas de Minkowski'); ax[1].set_ylabel('erro');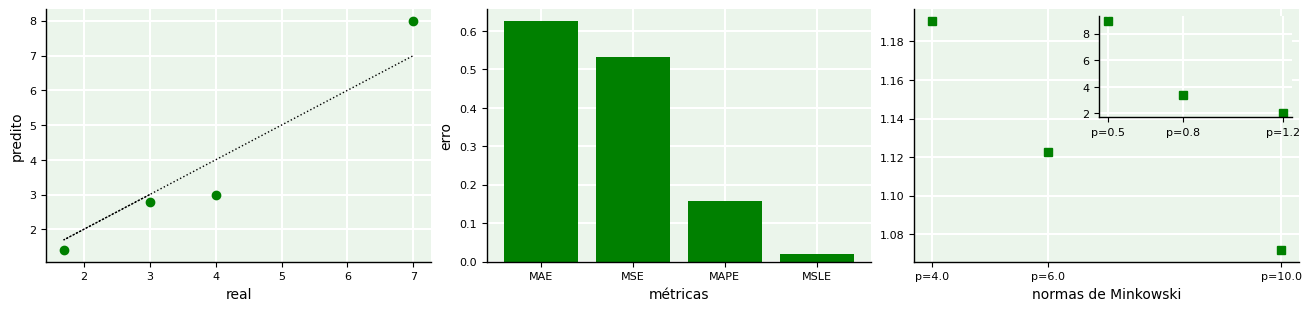
Percebe-se que cada métrica retorna um valor diferente para o erro entre os valores exatos e os aproximados. Cabe ao usuário interpretar qual faz mais sentido para o conjunto de dados em análise.
Aplicações¶
Erros pontuais na função de Airy¶
A função de Airy é solução da equação de Schrödinger da mecânica quântica. Ela muda o seu comportamento de oscilatório para exponencial. A fim de demonstrar como o erro é uma função, dependente do ponto onde é avaliado, criaremos uma função “perturbada” que simulará o papel de função de Airy aproximada, enquanto manteremos a função de Airy verdadeira como exata. Em seguida, criaremos outra função de utilidade para calcular diretamente o erro relativo pontual.
from scipy import special
import numpy as np
# Eixo das abscissas
x = np.linspace(-10, -2, 100)
# Funções de Airy e suas derivadas (solução exata)
A, aip, bi, bip = special.airy(x)
# Função de Airy perturbada
A_ = 1.152*A + 0.056*np.cos(x) Podemos usar o conceito de função anônima (lambda) para calcular diretamente o erro relativo para cada ponto . Assim, seja:
onde é a função de Airy aproximada e é a função de Airy exata. Então:
# Define função anônima para erro relativo
ai = lambda f,f_: abs(f_ - f)/abs(f)
# calcula erro relativo para função de Airy e sua aproximação
E_airy = ai(A,A_)A seguir, mostramos a plotagem das funções exatas e aproximadas, bem como do erro relativo pontual.
# Plotagem das funções
from matplotlib.pyplot import subplots
fig, ax = subplots(1, 2, figsize=(12,3), constrained_layout=True)
ax[0].plot(x, A, 'g-', label='Airy exata')
ax[0].plot(x, A_, 'g:', label='Airy aprox.')
ax[0].legend(loc='upper right', fontsize=8);
ax[1].plot(x, E_airy, 'g-', label='ER Airy')
ax[1].legend(loc='upper right', fontsize=8);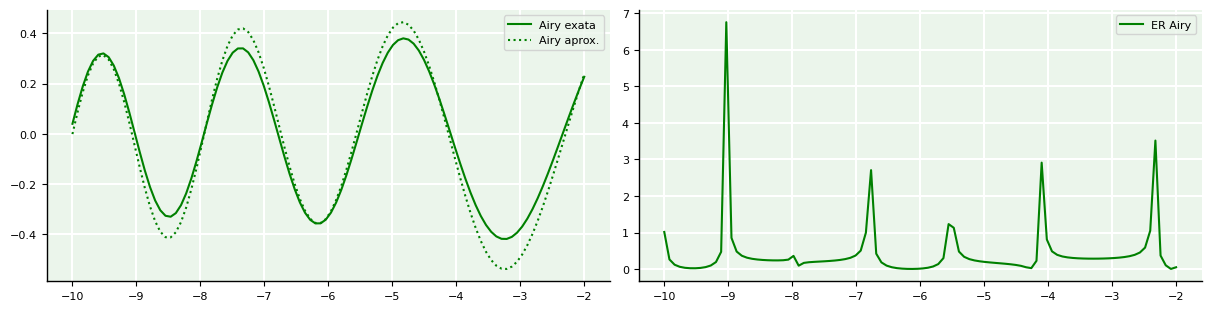
Avaliação de algoritmos de ordenação¶
Vamos considerar um cenário em que estamos avaliando a eficiência de dois algoritmos de ordenação: o algoritmo de ordenação por inserção (insertion sort) e o algoritmo de ordenação rápida (quick sort). Suponha que temos um conjunto de dados com 10.000 elementos e queremos comparar o tempo de execução teórico e o medido para ambos os algoritmos.
Consideremos:
: tempo de execução teórico do algoritmo.
: tempo de execução medido do algoritmo.
O insertion sort possui complexidade teórica de . Consideremos que o tempo teórico para 10.000 elementos seja de 50 segundos. O quick sort possui complexidade teórica de . Consideremos que o tempo teórico para 10.000 elementos seja de 2 segundos.
Após executar os algoritmos em uma máquina específica, suponhamos que tenhamos obtido os seguintes tempos de execução:
insertion sort: 55 segundos.
quick sort: 2.5 segundos.
O cálculo do erro relativo mostra que:
insertion sort:
quick sort: .
Ou seja, para o insertion sort, o erro relativo de -10% indica que o algoritmo demorou 10% mais do que o esperado, o que pode ser atribuído a fatores como sobrecarga de processamento ou otimizações que não foram realizadas. Para o quick sort, o erro relativo de -25% indica que o algoritmo demorou 25% mais do que o esperado, sugerindo que o algoritmo pode não ter se comportado da melhor maneira para este conjunto de dados específico, ou que a implementação usada não foi a mais eficiente.
Esses cálculos de erro relativo são essenciais para avaliar o desempenho dos algoritmos em ambientes reais, comparando-os com as expectativas teóricas. Eles ajudam a identificar discrepâncias que podem surgir devido a vários fatores, como características do hardware, implementações específicas do algoritmo, e peculiaridades dos dados de entrada.
Erros de precificação imobiliária por redes neurais¶
Vamos considerar um cenário onde estamos treinando uma rede neural para prever preços de imóveis com base em características como área, número de quartos, localização, etc. Para avaliar o desempenho da rede neural, usaremos o MSE e o MAE.
Dados do Conjunto de Treinamento e Teste
Temos um conjunto de dados com 1.000 amostras de preços de imóveis.
Treinamento da Rede Neural
A rede neural é treinada com um conjunto de treinamento e avaliada com um conjunto de teste.
Resultados do Conjunto de Teste
Valores reais dos preços dos imóveis:
Valores previstos pela rede neural
Cálculo do MSE
Cálculo do MAE
Interpretação dos Resultados
MSE: Um valor de 160 indica que, em média, os quadrados dos erros são relativamente altos. Como o MSE penaliza mais fortemente os grandes erros, este valor sugere que há algumas previsões com grandes discrepâncias.
MAE: Um valor de 12 indica que, em média, os erros absolutos entre as previsões e os valores reais são de 12 unidades monetárias. O MAE sendo menor que o MSE sugere que a maioria dos erros são pequenos, mas existem alguns grandes erros que estão influenciando o MSE.
Ajuste do Modelo: Se o MSE for muito maior que o MAE, isto pode indicar a presença de outliers que estão afetando negativamente o desempenho do modelo. Nesse caso, pode ser útil investigar os outliers e ajustar o modelo ou os dados de treinamento.
Avaliação de Desempenho
Ambas as métricas são úteis para avaliar a precisão do modelo, mas cada uma tem suas vantagens. O MSE é mais sensível a grandes erros, enquanto o MAE é mais intuitivo e menos sensível a outliers. O uso de MSE e MAE permite uma avaliação completa do desempenho de uma rede neural. Enquanto o MSE fornece uma visão detalhada dos erros grandes, o MAE oferece uma métrica mais robusta contra outliers, facilitando a interpretação dos resultados e a melhoria do modelo.
- Fasi, M., & Mikaitis, M. (2021). Algorithms for stochastically rounded elementary arithmetic operations in IEEE 754 floating-point arithmetic. IEEE Transactions on Emerging Topics in Computing, 9(3), 1451–1466. 10.1109/IEEESTD.2019.8766229
- Mallasén, D., Del Barrio, A. A., & Prieto-Matias, M. (2024). Big-PERCIVAL: Exploring the native use of 64-bit posit arithmetic in scientific computing. IEEE Transactions on Computers. 10.1109/TC.2024.3377890
- Milosavljević, A. (2020). Identification of salt deposits on seismic images using deep learning method for semantic segmentation. ISPRS International Journal of Geo-Information, 9(1), 24. 10.3390/ijgi9010024
- Shokouhi, P., Kumar, V., Prathipati, S., Hosseini, S. A., Giles, C. L., & Kifer, D. (2021). Physics-informed deep learning for prediction of CO2 storage site response. Journal of Contaminant Hydrology, 241, 103835. 10.1016/j.jconhyd.2021.103835
- Wang, Y.-W., Dai, Z.-X., Wang, G.-S., Chen, L., Xia, Y.-Z., & Zhou, Y.-H. (2024). A hybrid physics-informed data-driven neural network for CO2 storage in depleted shale reservoirs. Petroleum Science, 21(1), 286–301. 10.1016/j.petsci.2023.08.032